The implementation of intelligent traffic management systems and self-driving vehicles as central components of traffic planning demands precise and high-quality recognition of traffic objects. Deep learning is indeed becoming the game changing technology in computer vision and its specific application is object detection. Deep learning object detection plays a paramount role in coupled with the development of self-driving cars and smart traffic control. These systems depend on the chance of effectively and quickly recognizing items on the road in real-time. These systems are vital in increasing road safety, observing the real- time traffic hence directing traffic, thus decreasing incidences of traffic congestion. According to the facts obtained from the research [1], Road Traffic Accidents (RTA) are recognized to be among the leading causes of injury or death in the world [2]. In addition, the World Health Organization (WHO) [1] provides clear evidence that in 2018, traffic accidents ranked as the eighth leading cause of disease globally, accounting for 2.5% of all deaths worldwide. Similarly, according to the WHO statistics it is also revealed that big ratio of deaths happens every year. Yu et al. [2] offers an insight into traffic safety concern, which is a subfield of research in traffic analysis, traffic accident investigation, vehicle–collision identification, collision risk notification and collision elimination. Additionally, various intelligent systems have been developed to tackle traffic sign detection and recognition using computer vision (CV) and deep learning (DL) techniques. In this regard, an effective method for object recognition known as the YOLO (You Only Look Once) object detection algorithm is employed [3] [4] [5] [6] [7] [8] [9] [10] [11].
YOLO represents a more structured system that delivers both high speed and the necessary accuracy for real-time applications. In this way, traffic detection systems can detect traffic patterns that are regularly used thus precede in recognizing places that present more probability of accidents. It enables timely measures like modifying the period for which the traffic light remains green or red, changing the existing traffic pattern or possibility of using emergency services. For instance, if one intersection records many accidents regularly, traffic detection systems can inform the authorities to act and change either the signs or the signals on the roads for the better. Then, traffic detection systems enhance efficient responding to emergencies as they immediately inform services about accidents. Thus, early identification and intervention are critical to minimizing the extent of injuries and loss of life. These systems can give the exact location determinants that can help the emergency services to arrive at the scene much faster [3] [4] [5] [6] [7] [8] [9] [10] [11]. Traffic detection systems facilitate data-driven decision-making by supplying the collected data and the urban planners and the policymakers to study traffic flows and determine certain behaviors that cause mishaps. Data may reveal that certain types of roads or specific times of day are associated with a higher risk of accidents. This enables authorities to make proper changes in infrastructure that requires it, better road signs including, improved lighting or cycling and walking paths.
Since human error is a significant contributor to many accidents, traffic detection system provides a major relief to drivers in the event that a potential danger arises, these systems provide real-time information to alert drivers and enhance safety. Such systems can alert drivers about slowing down of traffic lights, objects on the road or adverse weather that can lead to accidents. In the most complex scenarios, traffic detection can be integrated with interactions between intelligent and semi-intelligent vehicles, enhancing overall transportation safety by minimizing human error. Summing up, it is possible to state that Traffic detection systems are beneficial for reducing the accident rates as they affect traffic openness, security measures, and autonomous automation. This can be financially quantified as a reduction in the toll of lives lost and injuries sustained on the roads, as well as the costs associated with automation.
Our proposed methodology delves into the application of two popular deep learning object detection frameworks: Two of such systems are namely YOLO [12] – ‘You only look once’ and the Faster Region-based Convolutional Neural Networks (CNNs) [13]. These models aim to identify the classes on a busy traffic road and tally the classes in real-time. Conversely, YOLO, which is built on convolutional neural networks, is one of the models used for object detection. These algorithms in particular has been selected because of their effectiveness and accuracy in contrast with other methods based on DL with regard to the processing time on GPUs, highest results regarding the most crucial values, and alacrity [14], [15], [16]. YOLO is a single-stage detector, making it faster, while Faster R-CNN is a two-stage detector, resulting in greater accuracy. Our objective is to assess these frameworks for detecting various traffic objects using the publicly available Kaggle dataset [17].
The aim of this project is to evaluate the frameworks based on the identification ratio, performance metrics, and their behavior in various environmental conditions. By comparing the strengths and weaknesses of both frameworks and considering the number of classes involved, we seek to establish a foundation for developing an effective traffic object detection system.
Object Detection Models
Faster RCNN
Faster R-CNN is deep learning object detection model and one of the latest additions to object detection family that features Region Proposal Network (RPN) along with fully convoluted network. The RPN effectively predicts ranges of feasible object locations in an image; computation time is faster than other techniques, for example, Selective Search. Thus, the fully convolutional network then annotates and regresses these proposals in order to recognize and localize objects in the image.
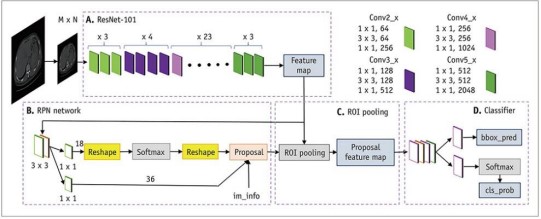
Figure 1. Architecture of Faster R-CNN [18]
YOLO
YOLO (You only look once) is real-time object detection algorithm. YOLO approach is quite unique as it processes the image in segments by predicting the bounding boxes and class probabilities for each segment in one pass while other approaches process the images one at a time. It also enables much faster processing rates than other methods of object detection making it suitable for real-time scenarios for example in real-time video analysis and surveillance as well as in AV applications. Another benefit of YOLO’s architecture is its capacity to detect multiple objects at once, and therefore offer a holistic perspective of the visual content stream of images and videos.
This paper is divided into three sections, the first section includes literature review, the second section consist of dataset and materials and methods, and the third section includes experimentation and results.
Literature Review
Population growth and increased accessibility to automobiles are contributing to traffic congestion and accidents. Traditional traffic monitoring methods are often labor-intensive, prone to errors, and inadequate for managing large volumes of data. Automated systems that utilize artificial intelligence and deep learning offer a better solution, delivering rapid and accurate data processing capabilities. However, the creation of a practical system capable of reliably recognizing multiple objects in real traffic environments, while minimizing false positives and false negatives remains a challenging task at this stage. The system's capability to respond efficiently to accidental conditions is essential, as is its ability to adhere to regulatory standards during emergencies. MAA Al-Qaness et al. [19] conducted a study that explores real-time vehicle classification and counting using the YOLOv3 algorithm, utilizing Python libraries such as NumPy, Pandas, and OpenCV. A neural network is trained on over 1,000 [20] images from various datasets (Pascal VOC [21], Open Images [22], COCO [23]) to detect and classify cars, trucks, and buses. The system achieved high vehicle counting accuracy (up to 98%) but experienced seasonal and time-based variations in detection and classification accuracy (e.g., afternoon: 88% detection, 73% classification).
Q Li, X Ding et al [24] utilized YOLOv4 (Python) to detect and count traffic objects in real-time (people, motorcycles, bicycles, cars, buses) to improve road safety for youngsters. The study achieved high accuracy rates for cars (88.89%) and buses (100%), although the detection rates for motorcycles and bicycles were not reported. This limits the model's effectiveness for these important vehicle classes. Additionally, the focus on car and bus accuracy suggested a potential class imbalance in the training data, which might hinder its ability to generalize to other object categories. J. Wang et al. [25] performed a study on traffic sign identification and classification employing YOLOv5, highlighting efficiency and utilizing a constrained dataset. To enhance accuracy, the standard YOLOv5 was upgraded with an improved Adaptive Attention Feature Pyramid Network (AF-FPN). The standard GIoU loss metric was substituted with the more straightforward Intersection over Union (IoU) for assessment, whereas the primary performance parameter was Frames Per Second (FPS). Achieving high FPS was tough due to the restricted training dataset, comprising merely 2,000 images. Dependence on established data augmentation techniques may insufficiently encompass the complete spectrum of changes present in actual traffic signs.
P Shinde et al [26] proposed a solution using real-time traffic light control. Cameras and YOLO were used to count vehicles and adjust lighting based totally on lane density and wait instances. This aimed to reduce congestion and emissions. However, the accuracy of YOLO for vehicle detection is probably limited, specifically for smaller gadgets or in difficult conditions. The accuracy of YOLO for vehicle detection in this scenario is unknown, and it might prioritize speed over precision, especially for smaller objects or lower quality footage. Despite these limitations, YOLO offers a promising step towards smarter traffic light control. N Youssouf - Heliyon et al [27] proposed a Convolutional Neural community (CNN) for traffic sign recognition and a YOLOv4-based object detection system for real-time traffic sign detection. The Faster R-CNN achieved an accuracy of 43.26% on the GTSRB dataset. The YOLOv4 model achieved a mean average precision (map) of 59.88% at a frame rate of 35 fps. The CNN for traffic sign recognition, although achieving high accuracy, requires
Almost 6.63 seconds to classify all images in the test set, making it slow for real-time applications. Faster R-CNN is slow (6 fps) for real-time applications. V Dalborgo et al [28] explored using YOLOv5, a deep learning model, to detect and classify traffic signs in Brazil, with a particular focus on signs obscured by vegetation. They compared different YOLOv5 versions (n, m, and x) and found that YOLOv5m offered the best compromise. YOLOv5m achieved good overall detection accuracy while maintaining similar performance to the more complex YOLOv5x. Importantly, it excelled at detecting vegetation occlusion with a precision of 92.9%. The researchers trained and tested their model using a dataset of 5631 images with 8065 annotations, encompassing 16 different traffic sign classes along with a specific class for vegetation occlusion. The hardware used for evaluation (i5 CPU, 16GB RAM, GTX920M GPU) might not be ideal for real-time applications. More powerful hardware is recommended.
Table 1. Literature review and study.

Methodology
This section outlines the process of integrating data into the traffic object detection project using YOLOv8 or Faster R-CNN. The data is sourced from Kaggle [17], an online platform that provides access to a wide variety of datasets for machine learning projects. Since our methodology emphasizes transportation items, meticulous attention is required for data cleansing and preparation. This entails verifying that the many class labels in the annotations correspond with both general and specific categories, including vehicles, buses, bicycles, motorbikes, and pedestrians. By redefining and reorganizing some of this data, the study aims to provide an enhanced dataset that better suits the models designed for analyzing and detecting these traffic objects. To effectively train and evaluate the object detection model, the dataset is typically divided into three distinct subsets: As with the previous methods, this has three stages namely training, validation and the testing. The training set is employed to bring the model into contact with many labeled examples in order that it establish good features with reference to different object classes. The validation set proves useful during the learning process as it offers information on the model’s performance and assists in tuning a model which has suffered from overfitting, a situation whereby a model gets overly trained to the extent that it cannot generalize to other examples. Lastly, the testing data allow evaluating the model’s accuracy on unseen data and can be considered as a rather realistic evaluation of its performance. Our model is designed to detect similar scenarios and situations much like the ones represented within the provided dataset, limiting its applicability to such contexts.

Figure 2. Dataset used in model.
The dataset includes 5,712 train images, 541 validation images, and 270 test images. The model is trained on workstation with RAM 32 GB and NVIDIA GeForce RTX 4080 Super GPU. To enhance computational efficiency, the device used CUDA model 12.4. This setup enabled effective utilization of the GPU, appreciably accelerating the trained and evaluation procedures. The combination of high RAM and a powerful GPU provided robust performance throughout the development of the version. We also purchase Colab [29] two times to run heavy models like Faster RCNN and YOLO.
The initial step involves converting the dataset labels to the Pascal VOC format for Faster R-CNN because it standardizes annotations, ensuring compatibility with pre-trained models. Pascal VOC organizes dataset labels into XML files containing item categories and bounding box coordinates, which manual the version in detecting and classifying objects throughout training and evaluation. Data preprocessing is a vital segment, concerning resizing pix to smaller dimensions, standardizing pixel depth values, and making use of numerous augmentation strategies inclusive of cropping, flipping, or color jittering to beautify the robustness of the version. A pre-skilled convolutional neural backbone ResNet50, asserted a vital role in deriving huge capabilities from a given image input. As a model, ResNet50, pretrained at the COCO dataset familiar with taking input characteristics including edges, shape, and texture that are vital for other detection levels. In the particular case, the Region Proposal Network (RPN) is held responsible for generating capability regions of interest which would contain objects. It works by moving a window over the feature maps that are generated using the spine network in an effort to locate the possible areas that contain devices.
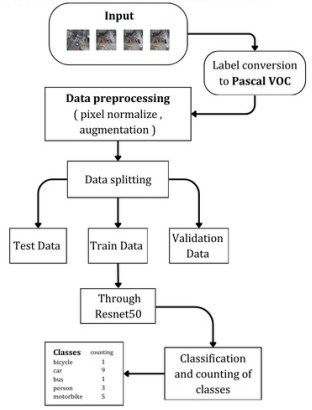
Figure 3. Faster RCNN Architecture Methodology of Traffic Object Detection
Following this, ROI pooling was employed to manner the proposed areas from the RPN, changing them into constant-size feature maps. This step is important as it standardized the scale of inputs for the subsequent layers, ensuring consistency and efficiency in processing. Finally, classification and bounding container regression are completed. The community performs these tasks simultaneously: classifying each region as either an object or background and refining the boundaries of those areas to enhance the accuracy of the bounding boxes. Classification is normally treated by means of a SoftMax layer, which assigns probabilities to one of a kind item lesson, while bounding box regression is managed by means of a regression layer, which adjusts the coordinates of the bounding containers to higher healthy the detected gadgets. This combined technique enhances both the detection accuracy and the precision of the object localization in the image.
(tx=(x-xa))⁄wa , (ty=(y-ya))⁄ha
tw=log(w⁄wa) , th=log(h⁄ha)
where x, y, w, h represents the predicted box's center coordinates, width, and height, and xa, ya, wa, ha represents the anchor box's center coordinates, width, and height. The classification loss for object detection in Faster R-CNN is often based on cross-entropy loss.
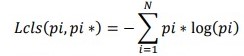
Where 𝑝𝑖 is the predicted probability of the of the response being equal to the desired value given the values of all the predictors. i-th class, and Pi∗ represents the ground truth label; if the current instance belongs to the correct class, then the ground truth label is 1, else it is 0. The bounding box regression loss is normally derived from the smooth L loss:
L_reg (ti,ti*)=smooth_(L_1 ) (ti,ti*)
The results are provided in the form of detected bounding boxes for each class, class label and class-based counting.
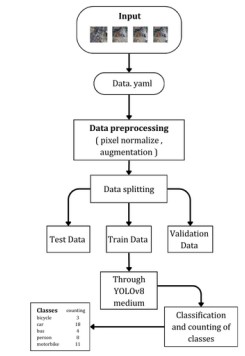
Figure 4. YOLO Architecture methodology of Traffic Object Detection
YOLO (You Only Look Once) is best for real-time packages due to its capability to speedy process snap shots while shooting contextual data [3] [4] [5] [6] [7] [8] [9] [10] [11]. To configure YOLO for effective training and validation, we make use of a configuration report, normally with a .Yaml extension, which details paths to the training and validation datasets, specifies the image size, and units' other parameters necessary for version operation. Data preprocessing is an important step in which the input images go through several transformations to optimize the model's performance. This includes resizing pictures to a fixed size for consistency, standardizing pixel intensities to normalize the data, and making use of augmentation strategies including cropping, flipping, and color balancing. These preprocessing steps are designed to beautify the robustness and generalization of the version, making sure accurate item detection across numerous situations. The dataset is then split into 3 distinct subsets: training, validation, and testing. This division is vital for comparing the model's overall performance and making sure that it generalizes properly to new, unseen information. During the training segment, ResNet-50, a neural community pre-educated on thousands and thousands of photos, is hired. ResNet-50 [30] is adept at spotting styles and capabilities within images, making it effective backbone for training YOLO in our dataset. Finally, YOLO performs bounding box prediction and class probability estimation. The model simultaneously predicts bounding containers and the associated class probabilities for each grid mobile within the image or input. This dual prediction capability allows YOLO to accurately determine the places of objects and classify them inside the image. For every bounding box, YOLO presents predictions concerning its position and the probability of each class, enabling precise object detection and classification. Center Coordinates (x, y):
𝑥 = 𝜎(𝑥𝖠) + 𝑐𝑥 , 𝑦 = 𝜎(𝑦𝖠) + 𝑐𝑦
where 𝑥^and y^ are the predicted coordinates, 𝑐𝑥 and 𝑐𝑦 is the coordinates of the cell which is a part of the grid. σ is commonly denoted sigmoid function or logistic function. Width (w) and Height (h)
𝑤 = 𝑝𝑤. exp(𝑤𝖠) , ℎ = 𝑝ℎ. exp(ℎ𝖠)
Where 𝑤^ and ℎ^ are the expected width and peak, and 𝑝𝑤 and 𝑝ℎ are anchor box dimensions. YOLO predicts a confidence on the bases of IoU score for each bounding box.
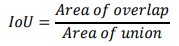
Where: Intersection over Union is the ratio of the Area of Overlap to the union of the predicted bounding box and the truth bounding box. Mathematically, it can be expressed as:
𝐼𝑜𝑈 =∣ 𝐴 ∩ 𝐵 ∣/∣ 𝐴 ∩ 𝐵 ∣
Where, A is predicted bounding box. B is the truth bounding box. ∣A∩B ∣ represents the area of overlap between the predicted and truth bounding boxes [31]. ∣A𝖴B∣ represents the area of union which can be calculated as the sum of the areas of the predicted and truth boxes minus the area of overlap.
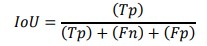
Where, Tp is true positive, Fn is false negative and Fp is false positive. Non-maximum suppression helps in minimizing the false positive results and at the same time increasing the overall likelihood of detection. The next phase which is the training loop entails going through the entire process from the input image to the weights’ update several times in the training data set it. Such considerations enable the model to undergo iterations that enhance the object detection it possesses. After training of the model, a certain data set is used to test the effectiveness and reliability of the model. It is crucial to measure the accuracy; thus, several evaluation metrics like Mean Average Precision (mAP) are used. Mean Average Precision is another important measure used to calculate the performance of an object detection model since it measures both precision that is the number of objects correctly detected, recall that is the proportion of all objects which have been detected with Intersection over Union threshold. For every class, obligatory metrics Average Precision (AP) enables the Precision-Recall curve integration.
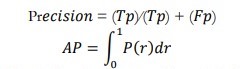
The mAP is calculated by finding Average Precision (AP) for each class and then average over a few classes for results.[33]
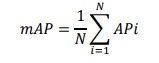
Experimentation and results
In the initial run, 55% of the images were correctly recognized, indicating the need for similarly training through additional epochs to enhance model’s overall performance. Training the Faster R-CNN model over three epochs took about 22.15 hours, highlighting each the computational demand for and time for better optimization.

Figure 5. Detected results of Faster RCNN
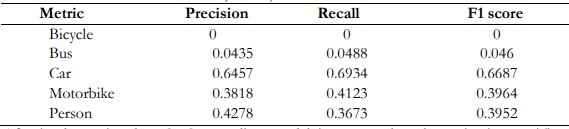
The evaluation of the Faster R-CNN model revealed blended performance across distinctive item instructions and achieved an affordable accuracy of 55.24%, it played well in general in detecting vehicles, with a precision of 0.6457 and an F1 Score of 0. 6687.The model struggled to recognize bikes and buses, which were not accurate, memory and F1 points. Also not recognize motorcycles and persons. This means that although the model is effective for some applications, such as cars, it needs more refinement and more balanced training data to improve its overall performance.
Table 2. Precision, Recall and F1 score of Faster RCNN
After implementing the YOLOv8 medium model, it was tested on the testing images. The model was trained for 10 epochs in 0.208 hours. During the initial testing, 93% of the images were recognizable, indicating the further training over additional epochs could enhance the program's results. The evaluation of the model shows strong overall performance universal, with an mAP50 (suggest Average Precision at 50% IoU) of 0.931 and an mAP50-95, indicating the model's effectiveness in detecting and appropriately localizing classes.

Figure 6. Detected results of YOLO
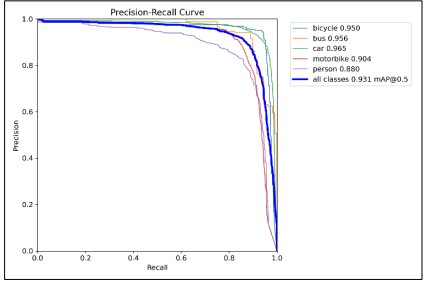
Figure 7. Precision- Recall curve of YOLO
The model performed particularly nicely with cars, buses and bicycle, achieved high precision reflected in their mAP50 rankings of 0.965 and 0.956, respectively. For bicycles and motorbikes, the model indicated solid overall performance, with mAP50 ratings of 0.950 and 0.904, even though the precision and recollect were slightly lower, for persons indicating a few rooms for improvement in detecting those training. Overall, at the same time as the version demonstrated high performance with cars, mainly bicycles and buses, it showed regions for improvement in detecting and localizing motorbikes and persons.
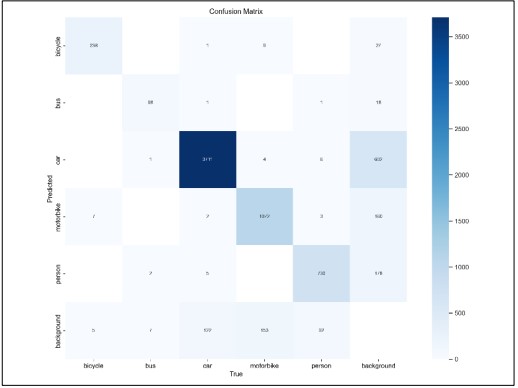
Figure 8. Confusion matrix of YOLO
The results indicate that the YOLO performs well and accurately, as it correctly identified the class in the diagonal elements. Off diagonal represents the misclassification of classes like 9 cars were classified incorrectly as buses. The graphs Figure 9. show that the decreasing training and validation loss curves indicate that the model is getting better in learning the data over time. Precision and recall values improved over time, indicating that the model is able to recognize objects with a low number of false alarms. Additionally, the mAP50 and mAP50-95 metrics demonstrate that the model performs well overall in object detection. The increase in these metrics indicates that the model is improving its ability to detect and classify objects as we transition from one IoU threshold to another.
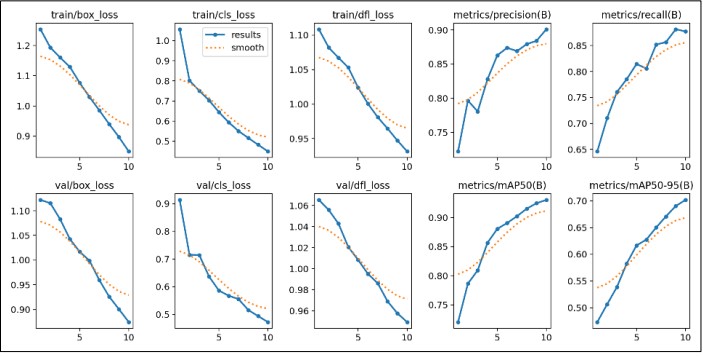
Figure 9. Graph of detected output in YOLO

Figure 10. Detected output in YOLO with labels
In comparison between YOLOv8 and Faster R-CNN, YOLO's single-stage architecture offers superior pace and accuracy, converging at some point of training, with improving performance metrics. However, there is still potential for improvement, particularly regarding the mAP50-95 metric. Potential areas for development include growing schooling epochs, adjusting hyperparameters, information augmentation, and exploring exclusive model architectures. By addressing these areas, the model's performance can be similarly more advantageous.
Faster R-CNN, despite its mild accuracy, is computationally pricey, limiting its suitability for real-time packages due to making it a greater sensible choice for real-time visitor's item detection. However, to draw a definitive conclusion, it is essential to evaluate the overall performance specific to each class
While each way exhibits comparable overall accuracy, YOLO and Faster R-CNN performance may additionally vary substantially while detecting particular item classes. A complete expertise of their strengths and weaknesses can be gained by cautiously analyzing their overall performance across special object lessons, enabling a knowledgeable selection for the maximum appropriate version in visitors item detection packages.
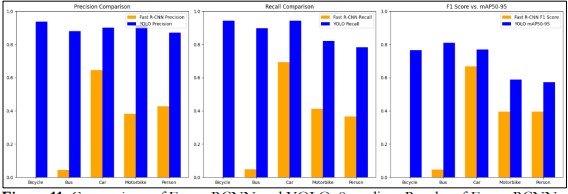
Figure 11. Comparision of Faster RCNN and YOLOv8 medium Results of Faster RCNN.
Discussion
As our methodology explain the evaluation between Faster R-CNN with the accuracy of 55% completed 3 epochs in 22 hours as very extensive model and YOLOv8 with the accuracy of 93% in 0.208 hours. We choose YOLOv8, as YOLOv8 is better than YOLOv5, YOLOv7 in terms of architecture, feature extraction, computational time, and performance of objects smaller. It also provides more capabilities in post-processing, options of customizations, compatibility with the recent frameworks better as compared to the generic filters making it more effective.
Conclusion and Future work
In conclusion this study assessed the overall performance of Faster R-CNN and YOLOv8 for real-time traffic detection, emphasizing the change-off between pace and accuracy. Faster R-CNN accomplished 55% accuracy after three epochs, presenting robust detection however restrained real-time applicability because of its computational demands. In evaluation, YOLOv8 reached 93% accuracy after 10 epochs in 0.206 hours, making it more suitable for actual-time use, even though with potentially lower accuracy. Both models were trained on a Kaggle dataset containing 5,712 images, utilizing a workstation equipped with 32 GB of RAM and an NVIDIA GeForce RTX 4080 Super GPU, powered by CUDA version 12.4. Additionally, we can enhance the results by exploring other deep learning technologies. In future we will work for the better detection of bicycles and pedestrians by using Efficient and SSD
Acknowledgement
The authors thank to MNS UET for letting us to use their NVIDIA GeForce RTX 4080 Super GPU.
Author’s Contribution
This research is a team work. all authors contributed equally.
Conflict of interest
The authors declare no conflict of interest regarding to the publication of paper.
Project details
Nil
