To see the environment and gather visual information humans rely on their eyes. The visually impaired person uses assistive technology which is referred to as blind and visually impaired (BVI) people. For the 2.2 billion people who are suffering from vision impairment worldwide, it would be difficult daily if they couldn't see or identify objects in their environment [1][2]. This disorder can cause partial blindness or total blindness which has a consequent negative impact on an individual's capacity to read, recognize faces, and navigate their surroundings safely. These difficulties impair their freedom and their standard of living [3]. The increasing global incidence of visual impairments highlights the significant need for practical solutions that can enhance accessibility and offer substantial assistance [4]. According to the forecasts the number of people who are suffering from vision impairment has significantly growth, as shown in Figure 1, which displays a remarkable enhancement of blindness and severe vision impairment between 1990 and 2050 [5]. This pattern highlights how important it is to create solutions that are specially designed to help the people of the community who are visually impaired.
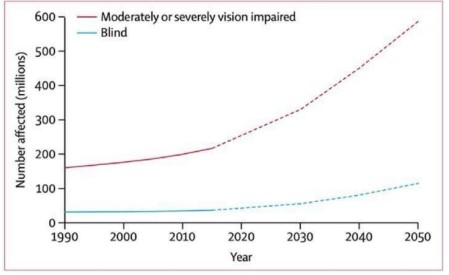
Figure 1. Statistical Diagram showing global trends and vision impairment [5]
Recent developments in Artificial Intelligence (AI) and deep learning have opened new avenues for addressing these problems [6]. Conventional picture description techniques, which mostly depend on human documentation or simple automated systems, frequently fail to provide visually impaired users with the comprehensive and accurate information that they require [7]. This restriction highlights the necessity for exponentially advanced systems that can provide comprehensive and contextually appropriate image descriptions [8]. To close these gaps, mostly LSTM networks and CNN are remarkable and effective for eliminating the colonial characteristics from the picture [9]. Even for producing textual descriptions that can be relevant and logical for the situation, LSTM is used [10]. By combining these techniques, modern picture captioning can be created to improve accessibility both visually and inwardly. The problems that are faced by visually impaired users can be addressed by recent developments in Artificial intelligence (AI) and deep learning [11]. Because of dependencies on human annotation and simple automated algorithms, conventional image description strategies fail to provide accurate and comprehensive information [12]. This focuses on the requirement of more and more complex systems that can provide comprehensive and contextually appropriate descriptions [13]. A solution is provided by deep learning technologies specifically CNN and LSTM networks. CNNs are very efficient at identifying complex characteristics in pictures [14].
Whereas LSTMs produce textual descriptions that are logical and suitable for the situation [15]. Advanced image captioning systems may be created, improving audiological feedback and visual accessibility by combining these technologies. They can also be gradually integrated with text-to-speech functionality [16]. Hybrid systems are available that combine LSTMs for sequence generation and CNNs for feature extraction which is used to create more effective picture captioning models. These algorithms produce systematically integrated descriptions that are suited for visually impaired users. Due to this, visually impaired users understand complicated scenes and recognize so many items. The ability of these models to focus on influential sectors of an image has been further enhanced by the integration of attention mechanisms, producing captions that are more dependable [17].
Moreover, when we are training a small data then data augmentation methods including rotation, flipping, and scaling enhance the model generalization [18]. We use text-to-speech modules that can convert these captions into auditory input due to this visually impaired people's freedom and quality of life will greatly improve [19]. Considerable methodological progress was established in this study to improve the suggested picture captioning system. VGG and Reset architectures were trained from scratch using datasets, with the use of weight-zero VGG and Reset architectures the model was improved through data augmentation and transfer learning approaches to produce extremely accurate and reflective picture descriptions [20]. The system's peak performance characteristics were made possible in large part by these strategies which include a validation accuracy of 0.9015 and a validation loss of 0.1766. During training early stopping was also used to avoid over-fitting and guarantee that the model performs effectively when applied to the fresh data. The efficiency of the model was further confirmed by BLEU score evaluation which showed notable improvements in caption quality. The addition of text-to-speech technology is an important advancement which is used to generate captions to be spoken and gives visually impaired users audible feedback. This Image captioning system not only integrates with the mobile app, but we can develop the hardware for the visually impaired people.
The paper is organized into several key sections. Section 2 focuses on the Literature Review where we discuss the numerous studies relating to deep learning and computer vision for various tasks such as Navigation and Object detection. Section 3 outlines Model Development, emphasizing the design and implementation of Vgg16 and Resnet50 architectures for feature extraction. Section 4 includes the information about the dataset whereas section 5 describes the development of a Custom Data Set to handle multiple captions per image, including the creation of input sequences and management of batching and shuffling. In section 6 research methods like Data Augmentation, Feature Extraction, and Image captioning are explained. In section 7 evaluation matrix including Accuracy and BLEU score is assembled. In section 8 we discussed the results of our experiments and compared validation accuracy and loss, alongside analysis of training accuracy. Finally, Section 9 offers a comprehensive result interpretation analyzing the outcomes, comparing model performance, and discussing the implementation of the result.
Literature Review
In recent years, significant advancements have been made in the field of assistive technologies for visually impaired individuals, particularly through the integration of Artificial Intelligence (AI). Studies have demonstrated the effectiveness of AI-based systems in enhancing mobility and accessibility for visually impaired people.
Pydala et al. [21] invented a smart stick for visually impaired persons. The system is trained to detect nearby objects, and for this reason, ultrasonic sensors are located. Additionally, it strengthens the visually impaired to navigate their surroundings safely and independently. The accuracy obtained by the model is almost 76.5% enhancing the trustworthiness of the system in real-world scenarios.
Upadhyay et al. [22] introduced a system named "Eye Road–An App that Helps Visually Impaired Peoples," an app designed to assist visually impaired people with advanced technologies. The Dataset consists of 20,000 images divided into 40 classifications. Yolov5 and OCR are two examples of models that are used for object detection and text reading, respectively. OCR achieves a recall rate of 70% and reaches its peak accuracy of 80 to 90. This study emphasizes the useful advantages and efficiency of the “eye road app”, highlighting the substantial potential of combining computer vision and machine learning technologies to improve mobility and independence for visually impaired users.
Kuriakose et al. [23] on developing a smartphone- advanced scene segmentation techniques, providing detailed feedback to the user and ensuring safer Navigation, uses 330,300 images for training, Methods used are CNN, GANs, and transfer learning giving precise accuracy rate of 88.6%.
Kumar et al. [24] reviewed various AI solutions designed to assist the visually impaired, emphasizing the role of deep learning in improving the accuracy and usability of these systems. Their work discussed models like SSD- MobileNetV2 and YOLO, which typically handle around 20 classes. This review provides a comprehensive overview of the current state of AI in assistive technologies, focusing on wearable devices and their integration with deep learning algorithms. To address the difficulties visually impaired people, encounter in indoor situations, Ajina et al. [25] developed an AI-assisted navigation system. The device uses "Deep-NAVI," a deep learning-based navigation assistant, to identify obstacles and lead users through unfamiliar areas. Three to four disease categories are targeted together with diabetic retinopathy, 80 classes of COCO datasets are trained, and Transfer learning techniques produce accurate predictions and faster model convergence the system is easy to use and handle.
Parenreng et al [26] invented an AI based on object detection using CNN. He utilizes 1000 images, methods like edge AI and Resnet for training and the model obtains an accuracy rate of 85%. It leverages to enhance the life of the visually impaired easily to navigate and make them move easily. Tamilarasan et al. [27] invented the "Blind Vision" system, which leverages AI to assist visually impaired individuals in navigating their surroundings. The system, designed to recognize 45 object categories, emphasizes the use of advanced AI algorithms to detect obstacles and provide real-time feedback to users.
Xie et al. [28] focus on liberating object detection with flexible expressions. He used a dataset of 10,578 images and obtained an accuracy rate (map) of 21.6% by utilizing techniques like REC and OVD. Faurina et al. [1] introduce the application of image captioning technologies to aid blind and visually impaired individuals in outdoor navigation. He used CNN and resnet512 architecture and obtained a precision rate of 91% on BLEU and 94.03% on ROUGH-L. It shows how sophisticated image captioning approaches can improve navigational help and improve the quality of life for visually impaired people, assisting their surroundings thoroughly and accurately. Table 1 shows the summary of the previous paper.
Table 1. Summary of previous papers
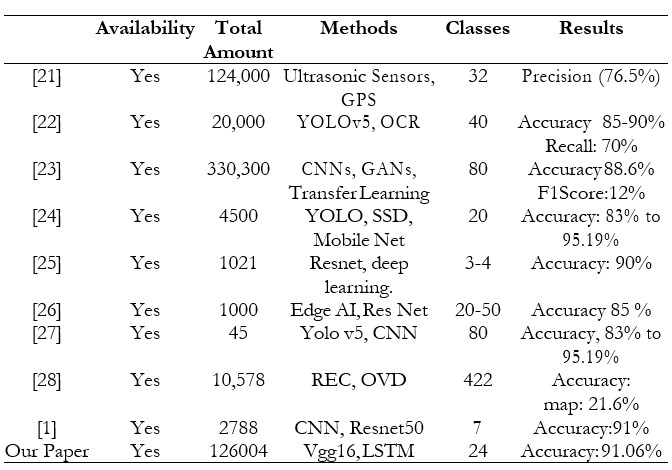
Vgg16 Architecture
The architecture of Vgg16 well-known for its accessibility and intensity that uses a series of convolutional layers with small 3x3 kernels which are followed by max-pooling layers. In our project, we retained a per-trained VGG model (e.g., VGG16 or VGG19) for its reliability in feature abstraction. The customization involved adjusting hyperparameters and discriminately reorientating certain layers to adjust the model to our specific data set. This structure optimized the high-dimensional feature representations learned from large-scale datasets and customized the performance of our task. The architecture of Vgg16 is shown in Figure 2 [29].
Figure 2. The Architecture of VGG16 Source [29]
Resnet Architecture
The Reset or Residual Networks deal with the obliterating optimization issues through residual connections that allow gradients to flow more efficiently during training shown in Figure 3 [30]. In this project, we retained a pre-trained Reset model (e.g., ResNet50) wherein the customization involve adjusting hyper-parameters and discriminately reorientating certain layers to adjust the modal to specific dataset characteristics.
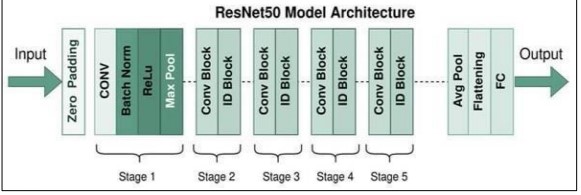
Figure 3. The Architecture of the Resnet50 Model [30]
Data Set
The dataset [31] consists of images and corresponding captions stored in a CSV file. Each image is linked to one or more captions. Before training, images are preprocessed by resizing them to a fixed size and normalizing pixel values, while captions are cleaned, tokenized, and converted into numerical sequences. The dataset is split into training and testing sets, which are given in Table 2. The captions are tokenized with "start seq" and "end seq" tokens for both sets and the size of the vocabulary is constantly maintained across the dataset.
Table 2. Dataset structure for training and testing
The maximum length of the caption is 15 words. A custom generator is used to manage multiple captions per image, handle input-output sequences, pair the features of the image with captions, and manage batching and shuffling. This structured strategy audit smooth and expedient model training and testing. The dataset utilized in this research initially consists of 24 distinct classes with a total of 1,600 instances. The distribution across these classes is shown in Figure 4 [31] is as follows: ATM-related (75), bench(120), bus(95), pharmacy (60), church (50), construction(70), door (85), Euro Banknote (40), food street(130), green signal (90), lift (55), luas (65), music related (80), playing kids (110), Pound Banknote (45), push button (50), red signal (100), stairs down (60), stairs up (65), trash related (90), wait (75), wallet (85), washroom (70), and wet floor (55).
In the context of the data-set scale, we started with the 8,000 original images. We applied augmentation techniques to enhance the dataset and improve model performance. The result of is a total of 126,004 augmented images. This augmentation process—through methods such as rotation, scaling, and flipping increases the dataset size and diversity. It plays a vital part in making our model more robust.
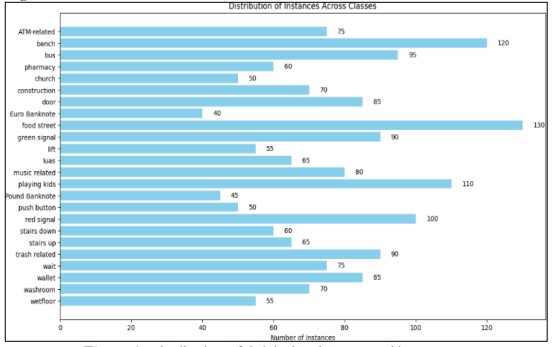
Figure 4. Distribution of Original and augmented images [31]
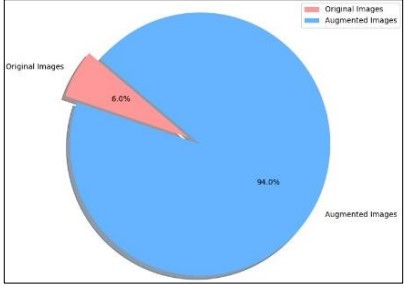
Figure 5. Distribution of Images Across Classes in Dataset
Figure 5 shows that the size of the dataset increases after applying Augmentation Techniques to each image.
Objective
The research has the following objectives:
• Developed Image Captioning System using Vgg16 and LSTM.
• Data augmentation techniques are used to increase the quality of the caption.
• Converted the caption-generated text into the speech.
• Compare the performance of Vgg16 and Resnet50, to generate image captioning.
Novelty
The following attributes show the novelty of our work.
• The dataset used in our work is based on 24 different categories.
• Different CNN architectures are used to increase the quality of captions.
• Integration of text with speech for visually impaired people.
Methodology
In the proposed methodology (Figure 6), we used CNN for extracting features from the image while LSTM is used to generate captions from an image. VGG16 captures complex spatial hierarchies with its deep convolutional layers, while to improve feature learning by solving disappearing gradient issues, ResNet50 uses residual. Ensuring the extraction of these features, data is fed into a sequence model commonly LSTM network, which operates the visual information to produce precise and contextually relevant captions as shown in Figure 9. Finetuning of hyperparameters is utilized to obtain high performance, like learning rate and batch size. For evaluating the quality of generated captions BLEU score is used, showing insights into how well the caption conveys the meaning of images. This strategy efficiently integrates advanced captioning with Cutting-edge feature methods. By fusing a powerful captioning model along with sophisticated extraction techniques exceptional descriptive outcomes are obtained.
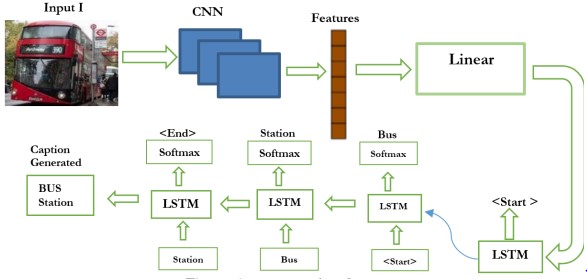
Figure 6. Image caption Generator
An image caption generator understands the content of an image and generates a relevant caption, with the help of computer vision and deep learning techniques. ImageNet dataset is used for the pre-trained models (Vgg16 and ResNet50). This enables them to acquire strong visual representations that contain attributes describing objects, texture, shape, and location of objects. Preliminary, an image goes further through the convolutional and pooling layers of these networks to obtain a descriptive feature. To generate captions and extraction of features then proceeded through the LSTM model. While the pyttsx3 library is used for converting generated captions into speech.
Preprocessing
The processing phase focused on creating an image captioning system optimized for the visually impaired. The approach was divided into several key phases, including data preprocessing, feature extraction using pre-trained models, and the design and training of a custom model architecture. During the preprocessing phase, the visual.token.txt file has the names of the images and their captions, where the dataset is initially loaded. The ‘image’ and ‘caption’ columns of this file are transformed into a Data Frame using the Panda’s package. Next, all of the text in the captions is converted to lowercase, and “start seq” and “end seq” are added to the beginning and end of each caption, respectively. This guarantees that all captions follow a uniform format as shown in Figure 7. Features retrieved from the dataset images using VGG16 and Reset50 models, with the best-performing model picked based on accuracy. The vocabulary size and maximum caption length are calculated from the processed captions. The dataset is then divided into training and testing sets, with 80% of the data utilized for training and 20% for testing in the original dataset and altered proportions in the augmented dataset. An LSTM model is deployed with early stopping to maximize training, ceasing when the validation loss does not improve for 100 epochs.
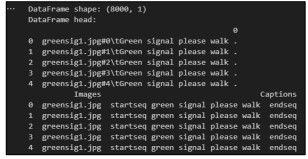
Figure 7. Data Frame with 'Image' and 'Caption' columns
In the preprocessing stage, the images were re-sized with the resolution of 224*224. Pixel values normalized to a range of [0, 1] to standardize the data which ensures consistent input scaling across all images. A series of data augmentation techniques were employed to enhance data-set diversity and improve model robustness.
Data Augmentation
Data augmentation strategies are applied to increase the data- set and improve model performance. Using the ‘Image Data Generator’ class in Kera’s, several techniques are used to boost data-set distinctiveness. Optimization parameters include rotation range which randomly rotates images by up to 30 degrees; width_shift_range and height_shift_range which allow horizontal and vertical shifts up to 20% of the image dimensions; shear_range which applies shear transformations up to 20 degrees and zoom_range which enables zooming in or out by up to 20%. Further, empty pixels are filled using fill_mode along with nearest pixel values whereas, images are turned horizontally using horizontal_flip. Figure 8 [31] shows the different versions of an image after applying data augmentation. Data augmentation helps this model to generalize better across multiple settings, enhancing its performance and ability to manage a range of visual conditions.
Table 3. Parameters of Data Augmentation

Table 3 highlights the typical parameters which are applied during the data augmentation to enhance the diversity of the training set. The vocabulary size of the dataset is 150 and the maximum length of the captions is 21 words. For instance, a sample caption from the dataset might be: "start seq” green signal please walk “end seq". To enhance the robustness of the model and prevent overfitting, early stopping was implemented with patience of 100 epochs. This approach monitors the validation loss during training and halts the process over 12 epochs. By stopping early, the model avoids overfitting and maintains its generalization capabilities, ensuring it performs well on unseen data.

Figure 8. Example of Image Augmentation Techniques (a). Original Image; (b) 90°left rotation; (c) 90° right rotation; (d) 180° Horizontal rotation; (e) 180° Vertical rotation [31]
Table 4. Image count in different datasets

Table 4 summarizes the number of images in three stages of dataset preparation: the initial dataset of normal images, the dataset after augmentation, and the combined dataset with both normal and augmented images.

Figure 9. Images with Captions [31]
Figure 9 [31] shows augmented images along with their Captions generated to make it understandable, reliable, and easy for visually impaired persons to navigate their surroundings.
Feature Extraction
Feature extraction was implemented for employing pre-trained models including VGG16 and Res Net which are known for their robust picture recognition skills. VGG16’s deep convolutional layers and max-pooling operations capture comprehensive spatial hierarchies while Res Net’s residual blocks manage the deconstruction gradient problem, increasing feature learning through shortcut connections. Images were re-sized and normalized to meet the specifications of the model. The recovered feature vectors are shown in Figure 10. with dimensions (1, 7, 7, 512), were then employed as inputs for the captioning model, helping the development of precise and contextually relevant image descriptions. This approach strengthens pre-trained networks, detaching the requirement for substantial training from scratch while ensuring precise feature extraction.
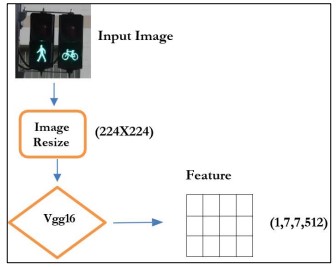
Figure 10. Extracting features from the input image
Evaluation Metrics
To obtain the accuracy and evaluation of the model, we use some tools to measure their presence or to make the model work more perfectly and effectively. Tools used in this experiment are,
• Accuracy
• BLUE
Accuracy
One of the most important evaluation metrics for evaluating a classification model's performance is accuracy. Its definition is the ratio of the total number of instances to the number of accurately predicted instances. In terms of math, it is stated as:
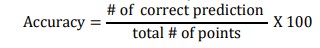
BLEU Score
A commonly used metric for assessing the quality of generated text in natural language processing tasks, such as image captioning, is the BLEU (Bilingual Evaluation Understudy) score. By evaluating the n-gram precision a measure of how well man words or sequences in the generated captions match those in the reference captions BLEU compares the machine-generated captions to the human-created reference captions.
Formula
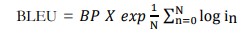

Experiment and Results
A high-performance system was used for the experiments according to the following specifications:
• CPU: AMD Ryzen 9 5900X
• GPU: NVIDIA GeForce RTX 4080 SUPER 16G VENTUS 3XOC
• Memory: 32 GB RAM
Res Net without Data Augmentation
By using Resnet50 and LSTM, the validation loss dropped from 0.4928 to 0.21977 by Epoch 27, while the training accuracy grew steadily from a starting point of training accuracy of 0.6801 and a validation accuracy of 0.6712 at Epoch 1. The validation loss was further improved to 0.19127 with the use of a learning rate adjustment at Epoch 33 as shown in Figure 10. The accuracy of the model increased further, but advancements slowed, and the model was early stopped when it attained its ideal performance without overfitting.
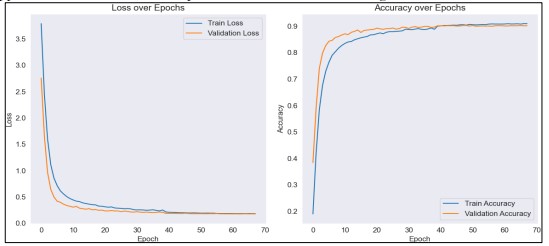
Figure 11. Performance using ResNet50 and LSTM for Image Captioning
Res Net50 with Data Augmentation
All images, original and augmented are preprocessed and scaled to meet the specifications of ResNet50's input. All image's features are taken out and put in a dictionary. Then, to make training data loading more efficient, the `Custom Data Generator` class is used. Batching, tokenizing captions, padding sequences, and data shuffling are all handled by this class. Two inputs are used to build the model: one for caption sequences and one for image features. While the caption sequences are processed through an LSTM layer after an embedding layer, the image features are flattened and run through a dense layer. Callbacks for model checkpointing, early pausing, and learning rate modifications are part of the training process. Based on validation loss, the best model is preserved during the training phase, which is tracked. The performance graph uses resnet50 with data augmentation and LSTM form image captioning is shown in Figure 12.
Vgg16 with Data Augmentation
In this study, we extracted features from a dataset image using the VGG16 model. To guarantee consistency and readability, the captions underwent preprocessing. The VGG16 model, which was pre-trained on the ImageNet dataset and did not include its top classification layers was used to extract features from images. To meet the input criteria of VGG16, the images underwent preprocessing and were scaled to a fixed dimension. Rotations, flips, and scaling were incorporated as augmentation approaches to add variety and improve the model's generalization across various image situations. To control the data loading procedure during model training, a unique data generator was created. This generator handled padding, conversion of caption text into integer sequence, and one-hot encoding. For training and testing purposes subset of the data set is reserved. For sequence processing model contains LSTM layers, for text an embedding layer, and image feature extraction for merging textual or image information. In order to prevent overfitting and maximize training, we trained the model using categorical cross-entropy loss, The model’s performance is measured using a range variety of callbacks, aiming to boost its accuracy and robustness while generating captions for images. For Image Captioning, the performance graph uses Vgg16 with data augmentation shown in Figure 13.
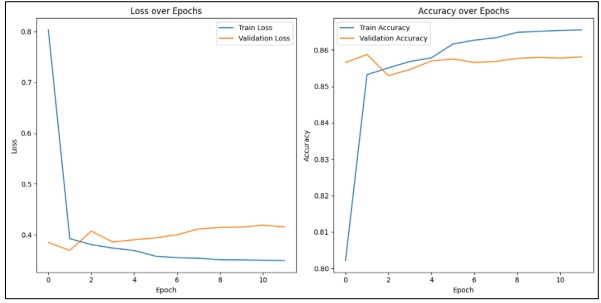
Figure 12. Performance using ResNet50 with Data Augmentation and LSTM for Image Captioning
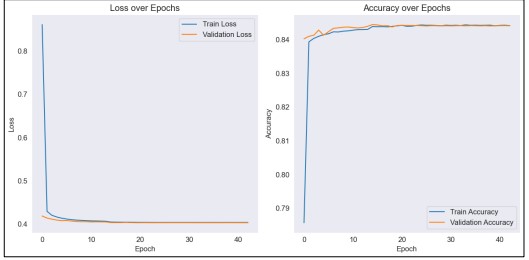
Figure 13. Performance using Vgg16 with Data Augmentation and LSTM for Image Captioning
Training of VGG16 without Data Augmentation
For captioning images, we use a VGG-based architecture. Initially, the dataset is split into training and testing data, and then using image attributes and tokenized captions custom model is assembled. We use a data generator to handle batches of image-caption pairs for training the model. Key callbacks are used to optimize the training process, including early stopping, reducing the learning rate, and model checkpointing. The model restores weights from epoch 58, when the best validation performance was noted, triggering early halting at epoch 63. With matching losses of 0.1776, the model obtained a training accuracy of 0.9106 and a validation accuracy of 0.9001. Following training, the top-performing model is saved to the designated directory, and matplotlib is used to show the training history, which includes trends in accuracy and loss shown in Figure 14.
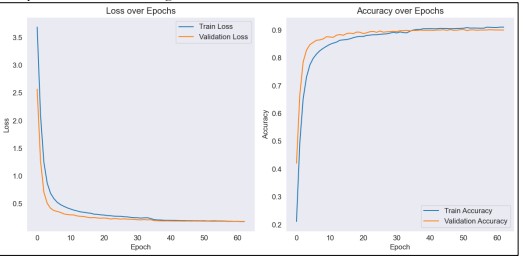
Figure 14. Performance using Vgg16 and LSTM for Image Captioning
BLEU Score of VGG16 Trained on Scratch
The BLEU scores for the VGG model that was trained using ImageNet differ considerably. The similarity between the actual caption "Be watchful wet floor ahead of you," and the predicted caption "Please mind your steps wet floor ahead of you" has a modest BLEU score of 0.446. With a score of 0.779, the prediction "be watchful upstairs ahead" compared to "please be watchful upstairs ahead" showed better alignment. A BLEU score of 1.0 indicated that perfect matches, like "this is a ten-pound note" and "this is a ten-pound note" reflected precise predictions.
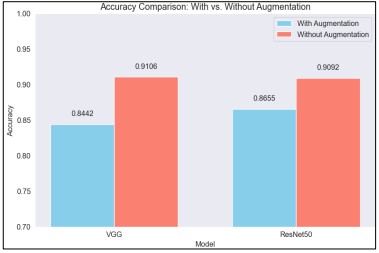
Figure 15. Accuracy Comparison with vs without Augmentation
Comparing the VGG16 and ResNet50 Models
Comparing the VGG16 and ResNet50 models with and without augmentation three comparative bar charts are created. The diagrams show training and validation accuracy. In terms of accuracy and training loss the speed of ResNet50 is better than VGG16 after augmentation is applied, while validation accuracy remains the same for both models. Both models display somewhat improved accuracy and reduced loss in the absence of augmentation. VGG and ResNet50 model performance was evaluated both with and without data augmentation. Without augmentation, the VGG model outperformed its augmented version. According to this, the accuracy of the ResNet50 model was 86.55% with augmentation and lower at 90.92% without it as shown in Figure 15. Although both models gain from augmentation, these findings show that the VGG model has a more noticeable decline in performance.
The VGG model retained a validation accuracy of 90.01% without augmentation and 84.41% with augmentation when analyzing validation accuracy shown in Figure 16. Without augmentation, the validation accuracy of the ResNet50 model was 90.15%; with augmentation, this dropped to 85.81%. The two models' validation accuracy trends are consistent, indicating that the performance loss brought on by augmentation is comparatively homogeneous.
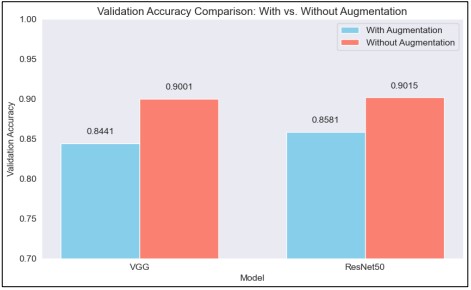
Figure 16. Validation Accuracy Comparison with vs without Augmentation
When it came to training loss, the VGG model showed a loss of 0.1776 without augmentation and a loss of 0.4037 with it. With and without augmentation, the training loss of the ResNet50 model was 0.1818 and 0.3489, respectively. The VGG model reported a validation loss of 0.1776 without augmentation, which increased somewhat to 0.4030 with augmentation. With augmentation, the validation loss of the ResNet50 model increased to 0.4152 from 0.1776. These findings show that, especially for the VGG model, augmentation significantly increases loss as shown in Figure 17. This implies that, although augmentation enhances generalization, it may also add complexity, which raises loss.
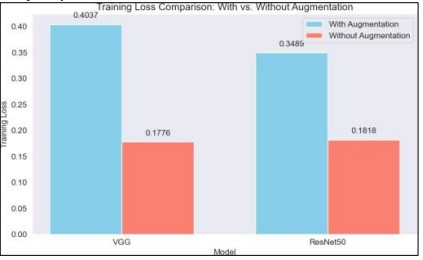
Figure 17. Training Loss Comparison with or without Augmentation
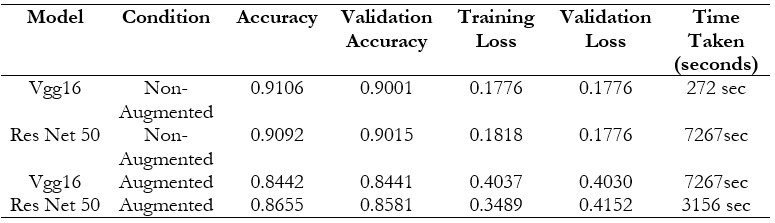
Key details about the performance of the VGG and ResNet50 models are revealed by contrasting them in both augmented and non-augmented scenarios. While training the VGG model without augmentation accuracy rate obtained was 0.9106, which was slightly greater than Resnet50’s 0.9092. Resnet50 performed better than VGG in terms of validation accuracy obtaining measures as 0.9015 in comparison to 0.9001. This demonstrates that resnet50 is capable of generating unseen data better than VGG, although VGG16 is suitable for the training set. This indicates that the validation accuracy and training loss (0.1818 vs 0.1776) of resnet50 is higher. Given that both models' validation losses are similar (0.1776), ResNet50 may be less prone to overfitting than VGG. Both models saw a decrease in accuracy when data augmentation was used, although the VGG model was more severely affected. The training accuracy of VGG decreased to 0.8442, while the validation accuracy dropped to 0.8441, indicating a major difficulty in adjusting to the enhanced data. The rise in loss metrics—a training loss of 0.4037 and a validation loss of 0.4030, respectively—which show a significant increase over the non-augmented condition, further supports this. ResNet50, on the other hand, demonstrated greater resistance to augmentation, as seen by a decline in accuracy to 0.8581 for validation and 0.8655 for training. Even though ResNet50's validation loss went up to 0.4152—higher than its training loss of 0.3489—the model continued to perform better than VGG in enhanced scenarios. The result shows the change in the capacity of two models founded by the state of data. Even though the performance of VGG is remarkable in non-magnified backgrounds, faces problems with augmented data. In comparison, Resnet50 handles the complications more accurately than VGG, even though in non-augmented conditions its performance is less than VGG16. It shows that Resnet50 is better for dealing with model accuracy trained from data augmentation in the real world. Table 5 shows the model comparisons obtained after treating data with or without augmentation.
Table 5. Vgg16 without augmentation excels over Resnet 50
Discussion
Some of the conventionally available facilities such as hardware navigation sticks for the visually impaired are somewhat inadequate. They are equipped with ultrasonic sensors for obstacle detection; however, they only have audio prompts if the previously mentioned conditions are met. This kind of conditional coding allows the simple execution of procedures but fails to handle actual scenarios. New technologies that are presented in the field of deep learning enable the development of more complex assistive systems. Such systems can handle full environments, instead of merely responding to specific stimuli. This broader interpretation of navigation spaces is more advantageous to the visually impaired. In-depth, deep learning improves physical perception and understanding of the surroundings. They are empowering free mobility for the blind and the visually impaired since they allow more integration. Table 1 shows the summary of all the previous papers. Table 1. shows that deep learning techniques are used for image captioning. According to Table 1, our proposed work can classify more than 23 classes with enhanced accuracy than others. Our methodology not only performs object detection or classification tasks but it is also used to generate image captioning with speech to visual impairment people.
Conclusion and Future Work
This research has demonstrated the promise of deep learning when it combines CNN networks with LSTM networks in improving image captioning for the visually impaired. In this part, the experimental result indicates that transfer learning and data augmentation combined with the dataset are successfully used for developing a more accurate and enhanced image description with a high accuracy of 0.9106 and a low validation loss of 0.1766. Also, there’s a text-to-speech feature that makes generated captions much more accessible. Future works will involve using other CNN architectures like Inception and Efficient Net to increase the reliability and accuracy of the captioning model. Moreover, description quality can be improved, and distinctive visual features can be identified through the addition of attention mechanisms and transformers.
Recommendation and Limitations
• Our dataset used only 24 sets of classes, while we can increase it more.
• In the dataset, we have few captions based on a single class, so we need to add more captions for each class from the dataset.
• We reached 91% maximum accuracy; we can increase the performance of our model by applying different deep learning state-of-the-art approaches.
