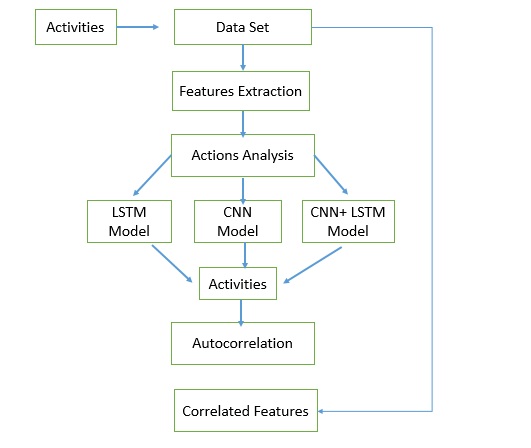
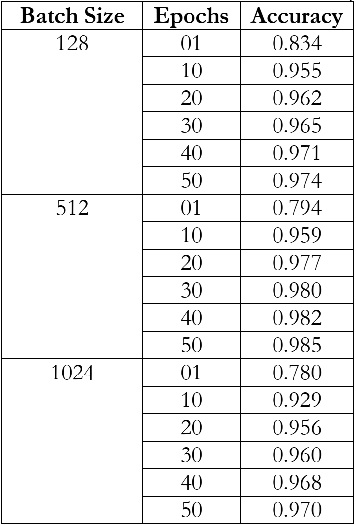
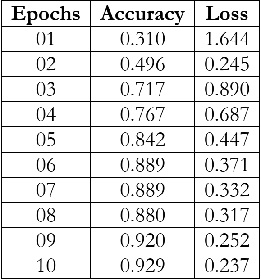
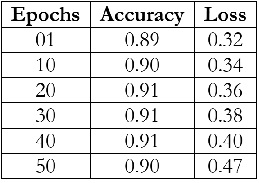
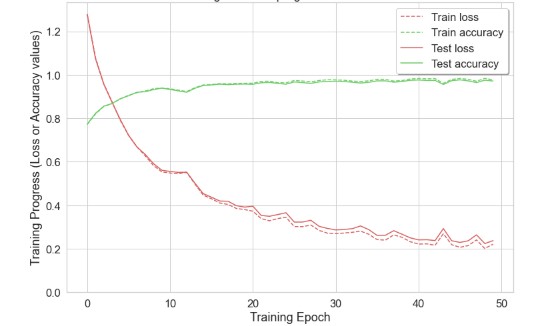
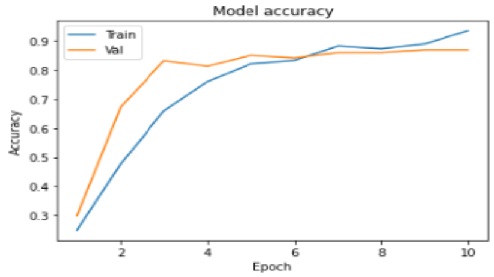
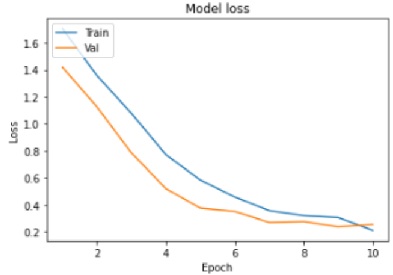
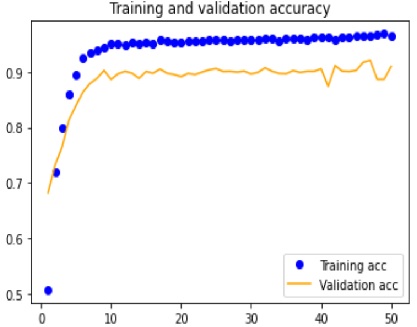
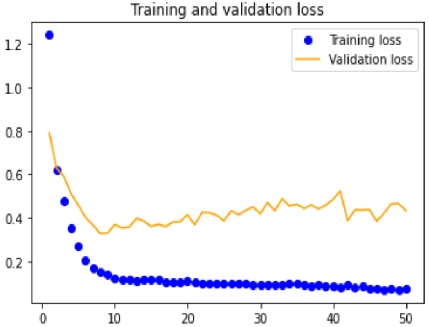
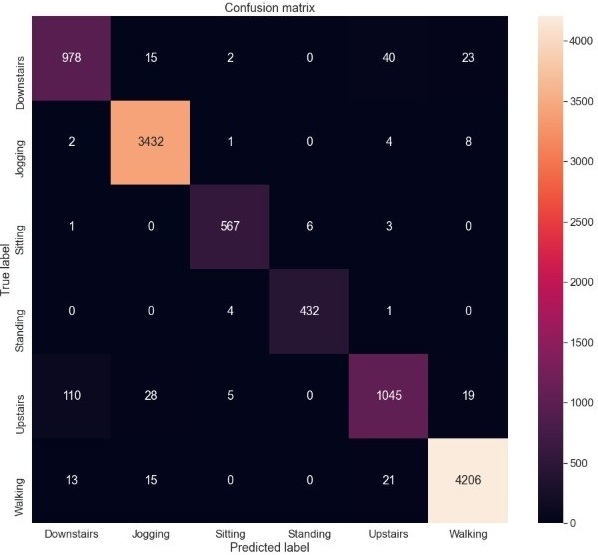
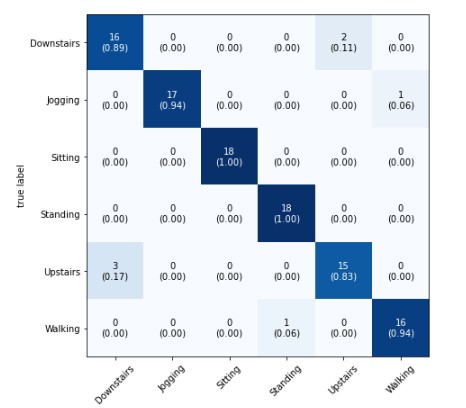
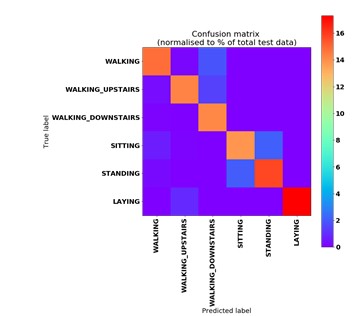
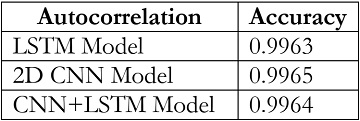
The tests driven out from our experiments are shown in the form of graphs and tables in this portion. Further,
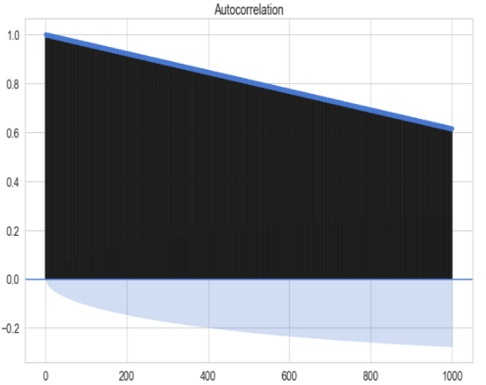
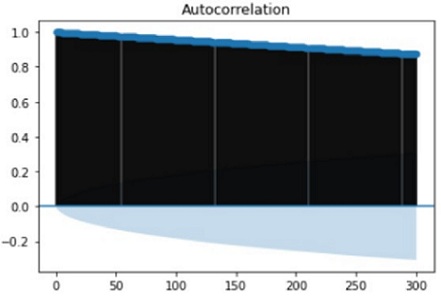
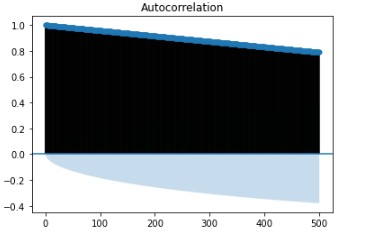
the three of our models (LSTM, CNN & CNN+ LSTM) went through the mechanism of autocorrelation. These models are one by one
checked and autocorrelation of our models with the activities is found and its result is represented in form of a graph for
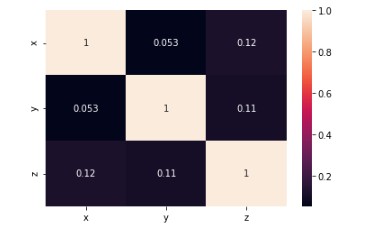
better understanding. At last, the correlation of all the features used in the models is found and this correlation of
features is represented in the form of a matrix.
The values in the matrix range from -1 to 1 so this means that if the value of a feature is:
• -1 means there is a
strong negative correlation between the features.
• 0 means there is no correlation between the features.
• 1
means there is a positive correlation between the features.
1. H. B. Zhang, Y. X. Zhang, B. Zhong, Q. Lei, L. Yang, J. X. Du and D. S. Chen, "A comprehensive survey of vision-based
human action recognition methods," Sensors, vol. 19(5), no. 1005, 2019.
2. . Staff, in 5th International Conference
on Advanced Technologies for Signal and Image Processing (ATSIP), 2020.
3. J. Xiong, L. Lu, H. Wang, J. Yang and G. Gui, "Object-level trajectories based fine-grained action recognition in
visual IoT applications," IEEE Access, vol. 7, pp. 103629-103638, 2019.
4. A. Jalal, S. Kamal and C. A.
Azurdia-Meza, "Depth maps-based human segmentation and action recognition using
full-body plus body color cues via recognizer engine," Journal of Electrical Engineering & Technology, vol. 14(1), pp.
455-461, 2019.
5. X. Gao, W. Hu, J. Tang, J. Liu and Z. Guo, " Optimized skeleton-based action recognition via
sparsified graph
regression," In Proceedings of the (pp.27th ACM International Conference on Multimedia, 2019 (october).
6. Y. Ji, F.
Xu, Y. Yang, N. Xie, H. T. Shen and T. Harada, "Attention transfer (ANT) network for view-invariant action
recognition," In Proceedings of the 27th ACM International Conference on Multimedia, pp. 574-582, 2019 (October).
7.
I. Vernikos, E. Mathe, A. Papadakis, E. Spyrou and P. Mylonas, "An image representation of skeletal data for action
recognition using convolutional neural networks," 2019.
8. G. Lin and W. Shen, "Research on convolutional neural
network based on improved Relu piecewise activation function,"
Procedia computer science, vol. 131, pp. 977-984, 2018.
9. X. Weiyao, W. Muqing, Z. Min, L. Yifeng, L. Bo and X.
Ting, "Human action recognition using multilevel depth motion
maps," IEEE Access, vol. 7, pp. 41811-41822, 2019.
10. G. Yao, T. Lei and J. Zhong, " A review of
convolutional-neural-network-based action recognition.," Pattern
Recognition Letters, vol. 118, pp. 14-22, 2019.
11. L. Wang, D. Q. Huynh and P. Koniusz, "A comparative review of
recent kinect-based action recognition algorithms,"
IEEE Transactions on Image Processing, vol. 29, pp. 15-28, 2019.
12. N. Hussein, E. Gavves and A. W. Smeulders,
"Timeception for complex action recognition.," In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 254-263, 2019.
13. C. Yang, Y. Xu, J. Shi, B.
Dai and B. Zhou, "Temporal pyramid network for action recognition," In Proceedings of the
IEEE/CVF conference on computer vision and pattern recognition, pp. 591-600, 2020.
14. B. Jiang, M. Wang, W. Gan, W.
Wu and J. Yan, "Stm:Spatiotemporal and motion encoding for action recognition.," In
Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2000-2009, 2019.
15. Y. Li, B. Ji, X.
Shi, J. Zhang, B. Kang and L. Wang, "Tea:Temporal excitation and aggregation for action
recognition," In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 909-918, 2020.
16. N. Jaouedi, N. Boujnah and M. S. Bouhlel, "A new hybrid deep learning model for human action recognition," Journal of
King Saud University-Computer and Information Sciences, vol. 32(4), pp. 447-453, 2020.
17. Z. Wang, Q. She and A.
Smolic, "Action-net: Multipath excitation for action recognition," In Proceedings of the
IEEE/CVF conference on computer vision and pattern recognition, pp. 13214-13223, 2021.
18. M. Li, S. Chen, X. Chen,
Y. Zhang, Y. Wang and Q. Tian, "Actional-structural graph convolutional networks for
skeleton-based action recognition," In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.
3595-3603, 2019.
19. K. Gedamu, Y. Ji, Y. Yang, L. Gao and H. T. Shen, "Arbitrary-view human action recognition via
novel-view action
generation," Pattern Recognition, vol. 118, p. 108043, 2021.
20. J. Li, X. Liu, M. Zhang and D. Wang, "
Spatio-temporal deformable 3d convnets with attention for action recognition,"
Pattern Recognition, vol. 98, p. 107037, 2020.
21. K. Cheng, Y. Zhang, X. He, W. Chen, J. Cheng and H. Lu,
"Skeleton-based action recognition with shift graph
convolutional network," In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 183-192,
2020.
22. L. Shi, Y. Zhang, J. Cheng and H. Lu, "Skeleton-based action recognition with directed graph neural
networks," In
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7912-7921, 2019.
23. D. Li, Z. Qiu, Y. Pan, T. Yao, H. Li and T. Mei, "Representing videos as discriminative sub-graphs for action
recognition," In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3310-3319, 2021.
24. P. Koniusz, L. Wang and A. Cherian, "Tensor representations for action recognition," IEEE Transactions on Pattern
Analysis and Machine Intelligence, vol. 44(2), pp. 648-665, 2021.
25. W. Hackbusch and S. Kühn, "A new scheme for
the tensor representation," Journal of Fourier analysis and applications,
vol. 15(5), pp. 706-722, 2019.
26. H. Yang, C. Yuan, B. Li, Y. Du, J. Xing, W. Hu and S. J. Maybank, "Asymmetric 3d
convolutional neural networks for
action recognition," Pattern recognition, vol. 85, pp. 1-12, 2019.
27. Y. Li, Y. Chen, X. Dai, D. Chen, M. Liu, L.
Yuan and N. Vasconcelos, "MicroNet: Towards image recognition with
extremely low FLOPs," arXiv preprint, p. 2011.12289, 2020.
28. T. Özyer, D. S. Ak and R. Alhajj, "Human action
recognition approaches with video dataset," A survey. Knowledge-Based
Systems, vol. 222, p. 106995, 2021.
29. D. Ghadiyaram, D. Tran and D. Mahajan, "Large-scale weakly-supervised
pre-training for video action recognition," In
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12046-12055, 2019.
30. Y.
Song, J. Vallmitjana, A. Stent and A. Jaimes, "Tvsum: Summarizing web videos using titles," In Proceedings of the
IEEE conference on computer vision and pattern recognition, pp. 5179-5187.