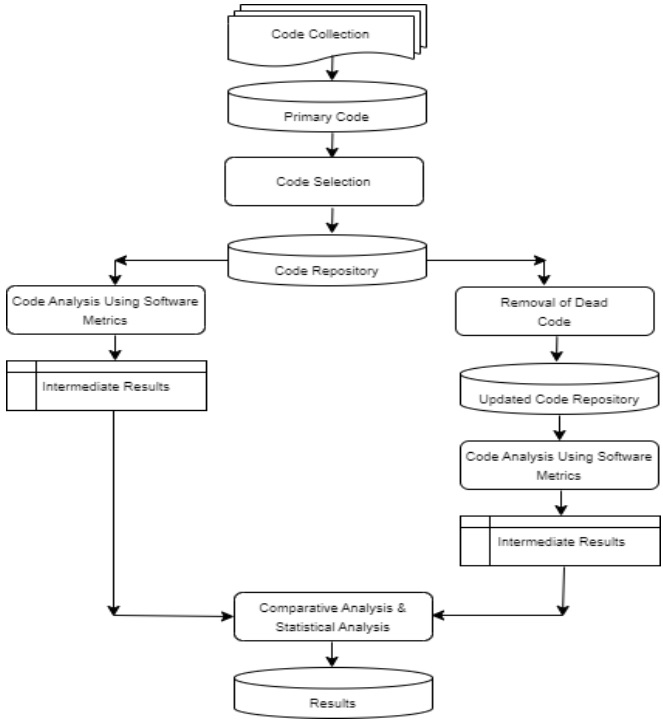
Open-source code is a widely acknowledged method used in software development to
reduce development time, budget, and other scarce resources. On one hand, predeveloped
repositories of source code offer numerous advantages; however, on the other hand, this code
can be of high complexity, large size, and difficult to maintain. This study analyzed Python opensource code to determine its efficiency, conciseness, and ease of maintenance.
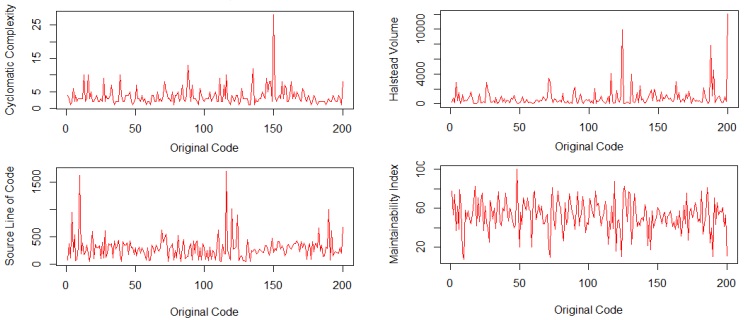
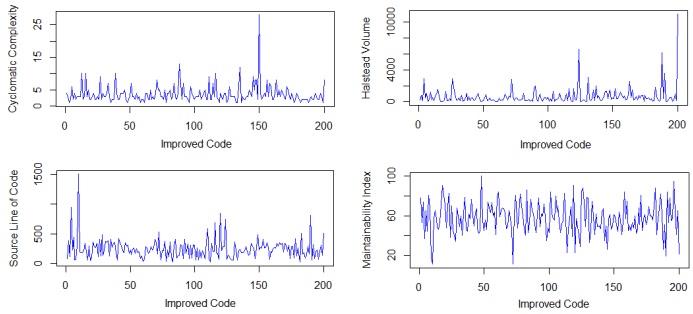
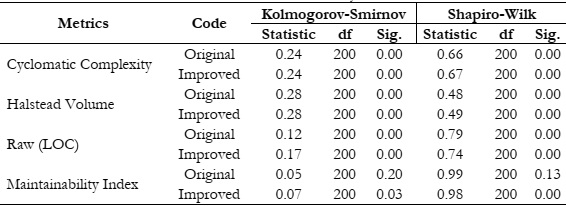
The two-stage analysis of the code revealed that the average cyclomatic complexity of
the original code was 3.76, compared to 3.64 for the improved code. As a result, the percentage
difference of 3.24% indicates that the testability and cyclomatic complexity of open-source code
can be enhanced through the removal of dead code.
The average Halstead volume of the original code was 803.24, compared to 640.56 for
the improved code. Their percentage difference of 22.54 clearly indicates that the volume of
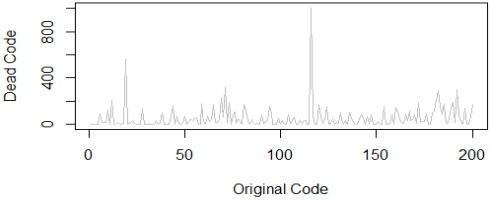
open-source programs is relatively low. This is attributed to the presence of dead code, and thus,
the removal of this dead code could effectively manage program volume.
The average raw size of the original code was 298.78, compared to 244.35 for the
improved code. Their percentage difference of 20.04 clearly indicates that the size of opensource programs is relatively higher than that of its corresponding improved code. This suggests
that open-source code contains dead code that could be deleted, potentially reducing the overall
code size.
The average maintainability index of the original code was 57.66, compared to 52.30 for
the improved code. Their percentage difference of 9.75 clearly indicates that the open-source
code is difficult to maintain within the scope of the present study and the analyzed dataset.
The overall study concluded that open-source code is a valuable asset for commercial
software development. However, the blind use of this code is not useful, as the code may have
high complexity and size, which will naturally complicate the software, increase its size, and
affect maintainability. A detailed analysis of open-source code, including the removal of dead
code, is necessary before its use in software development or in any other application.
The novelty of this study lies in the quantitative analysis of code and results, which will
be useful for software engineering and researchers in the future. However, there are several
limitations to the present research: i) only 200 source codes were examined in the study, ii) only
a few elements were examined during the study, iii) a single programming language was
considered for the study. In the future, a larger programming corpus will be examined from
multiple perspectives, and similarly, multiple programming languages will be considered for the
study.
[1] “INTRODUCTION TO COMPUTER PROGRAMMING (BASIC).”https://www.researchgate.net/publication/317182495_INTRODUCTION_TO_COMPUTER_PROGRAMMING_BASIC (accessed Oct. 02, 2023).
[2] “Python current trend applications-an overview.”https://www.researchgate.net/publication/344569950_Python_current_trend_applications-an_overview (accessed Oct. 02, 2023).
[3] M. S. Naveed and M. Sarim, “Two-Phase CS0 for Introductory Programming: CS0 forCS1,” Proc. Pakistan Acad. Sci. A. Phys. Comput. Sci., vol. 59, no. 1, pp. 59–70, Jun.2022, doi: 10.53560/PPASA(59-1)710.
[4] “Software Developer Jobs Will Increase Through 2026 | Dice.com Career Advice.”https://www.dice.com/career-advice/software-developer-jobs-increase-2026 (accessedOct. 02, 2023).
[5] M. S. Naveed, “Comparison of C++ and Java in Implementing IntroductoryProgramming Algorithms,” Quaid-E-Awam Univ. Res. J. Eng. Sci. Technol.Nawabshah., vol. 19, no. 1, pp. 95–103, Jun. 2021, doi: 10.52584/QRJ.1901.14.
[6] A. Moss, R. Schluntz, and P. A. Buhr, “C: Adding modern programming languagefeatures to C,” Softw. Pract. Exp., vol. 48, no. 12, pp. 2111–2146, Dec. 2018, doi:10.1002/SPE.2624.
[7] “View of C in CS1: Snags and Viable Solution.”https://publications.muet.edu.pk/index.php/muetrj/article/view/91/45 (accessedOct. 02, 2023).
[8] C. Sanderson and R. Curtin, “Armadillo: a template-based C++ library for linear algebra,” J. Open Source Softw., vol. 1, no. 2, p. 26, Jun. 2016, doi:10.21105/JOSS.00026.
[9] J. Gosling, B. Joy, G. Steele, G. Bracha, and A. Buckley, “The Java ® Language Specification Java SE 8 Edition,” 1997.
[10] G. O’Regan, “The Innovation in Computing Companion,” Innov. Comput. Companion, 2018, doi: 10.1007/978-3-030-02619-6.
[11] C. Severance, “Guido van Rossum: The early years of python,” Computer (Long. Beach.Calif)., vol. 48, no. 2, pp. 7–9, Feb. 2015, doi: 10.1109/MC.2015.45.
[12] G. M. M. Bashir and A. S. M. L. Hoque, “An effective learning and teaching model for programming languages,” J. Comput. Educ. 2016 34, vol. 3, no. 4, pp. 413–437, Jul.2016, doi: 10.1007/S40692-016-0073-2.
[13] D. Rodriguez, I. Herraiz, and R. Harrison, “On software engineering repositories and their open problems,” 2012 1st Int. Work. Realiz. AI Synerg. Softw. Eng. RAISE 2012 - Proc., pp. 52–56, 2012, doi: 10.1109/RAISE.2012.6227971.
[14] L. Ardito, R. Coppola, L. Barbato, and D. Verga, “A Tool-Based Perspective onSoftware Code Maintainability Metrics: A Systematic Literature Review,” Sci. Program.,vol. 2020, 2020, doi: 10.1155/2020/8840389.
[15] D. Knight, S. Torri, and T. Bhowmik, “A Preliminary Critical Review of the Impact of Three Popular Development Practices on Source Code Maintainability,” Proc. - Int. Comput. Softw. Appl. Conf., vol. 2023-June, pp. 1633–1637, 2023, doi: 10.1109/COMPSAC57700.2023.00252.
[16] P. Quality, F. Sholichin, M. Adham, S. A. Halim, and M. Firdaus Bin Harun, “REVIEW OF IOS ARCHITECTURAL PATTERN FOR TESTABILITY,” J. Theor. Appl. Inf. Technol., vol. 15, no. 15, 2019, Accessed: Oct. 02, 2023. [Online]. Available: www.jatit.org
[17] V. Garousi, M. Felderer, and F. N. Kılıçaslan, “A survey on software testability,” Inf. Softw. Technol., vol. 108, pp. 35–64, Apr. 2019, doi: 10.1016/J.INFSOF.2018.12.003.
[18] M. S. Naveed, “Correlation Between GitHub Stars and Code Vulnerabilities,” J. Comput. Biomed. Informatics, vol. 4, no. 01, pp. 141–151, Dec. 2022, doi:10.56979/401/2022/111.
[19] “Analysis of Code Vulnerabilities in Repositories of GitHub and Rosettacode: A comparative Study | International Journal of Innovations in Science & Technology.” https://journal.50sea.com/index.php/IJIST/article/view/289 (accessed Oct. 02, 2023).
[20] M. Scotto, A. Sillitti, and G. Succi, “AN EMPIRICAL ANALYSIS OF THE OPEN SOURCE DEVELOPMENT PROCESS BASED ON MINING OF SOURCE CODE REPOSITORIES,” https://doi.org/10.1142/S0218194007003215, vol. 17, no. 2, pp. 231–247, Nov. 2011, doi: 10.1142/S0218194007003215.
[21] P. Bhattarai, M. Ghassemi, and T. Alhanai, “Open-source code repository attributes predict impact of computer science research,” Proc. ACM/IEEE Jt. Conf. Digit. Libr., Jun. 2022, doi: 10.1145/3529372.3530927.
[22] D. L. Vu, I. Pashchenko, F. Massacci, H. Plate, and A. Sabetta, “Towards Using Source Code Repositories to Identify Software Supply Chain Attacks,” Proc. ACM Conf. Comput. Commun. Secur., pp. 2093–2095, Oct. 2020, doi: 10.1145/3372297.3420015.
[23] R. Raducu, G. Esteban, F. J. R. Lera, and C. Fernández, “Collecting Vulnerable Source Code from Open-Source Repositories for Dataset Generation,” Appl. Sci. 2020, Vol. 10, Page 1270, vol. 10, no. 4, p. 1270, Feb. 2020, doi: 10.3390/APP10041270.
[24] B. Norick, J. Krohn, E. Howard, B. Welna, and C. Izurieta, “Effects of the number of developers on code quality in open source software: A case study,” ESEM 2010 - Proc. 2010 ACM-IEEE Int. Symp. Empir. Softw. Eng. Meas., 2010, doi: 10.1145/1852786.1852864.
[25] D. R. Wijendra, S. Lanka, and K. P. Hewagamage, “Analysis of Cognitive Complexity with Cyclomatic Complexity Metric of Software General Terms,” Int. J. Comput. Appl., vol. 174, no. 19, pp. 975–8887, 2021.
[26] “The Impact of Language Syntax on the Complexity of Programs: A Case Study of Java and Python | International Journal of Innovations in Science & Technology.” https://journal.50sea.com/index.php/IJIST/article/view/339 (accessed Oct. 02, 2023).
[27] M. Shepperd, “A critique of cyclomatic complexity as a software metric,” Softw. Eng. J., vol. 3, no. 2, p. 30, 1988, doi: 10.1049/SEJ.1988.000310.1049/SEJ.1988.0003.
[28] A. Odeh, M. Odeh, N. Odeh, and H. Odeh, “Machine Learning Model for Measuring Cyclomatic Complexity of Source Code,” 2023 Int. Conf. Intell. Comput. Commun. Netw. Serv. ICCNS 2023, pp. 149–153, 2023, doi: 10.1109/ICCNS58795.2023.10193630.
[29] M. S. naveed, “Measuring the Programming Complexity of C and C++ using Halstead Metrics:,” Univ. Sindh J. Inf. Commun. Technol. , vol. 5, no. 4, pp. 158–165, 2021, Accessed: Oct. 02, 2023. [Online]. Available: https://sujo.usindh.edu.pk/index.php/USJICT/article/view/4073
[30] G. Yenduri and V. Naralasetti, “A Nonlinear Weight-Optimized Maintainability Index of Software Metrics by Grey Wolf Optimization,” Int. J. Swarm Intell. Res., vol. 12, no. 2, pp. 1–21, Apr. 2021, doi: 10.4018/IJSIR.2021040101.