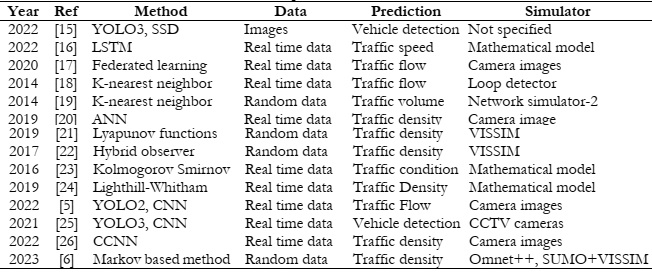
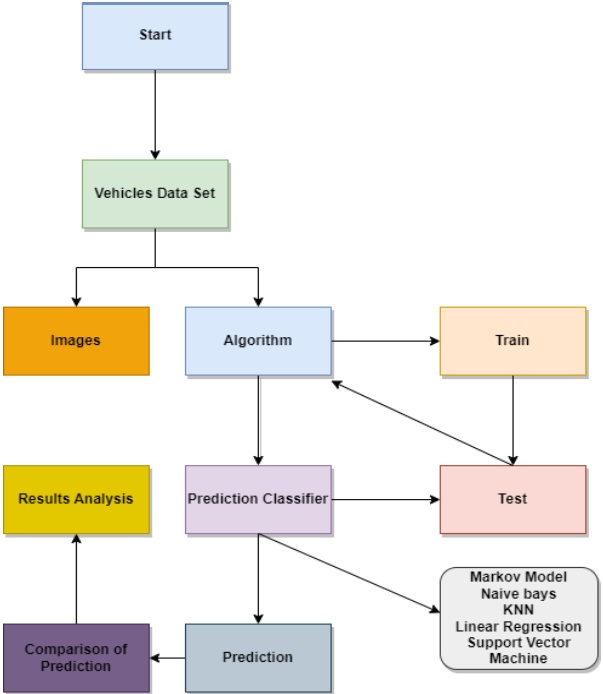
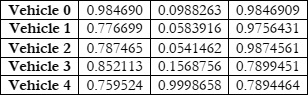
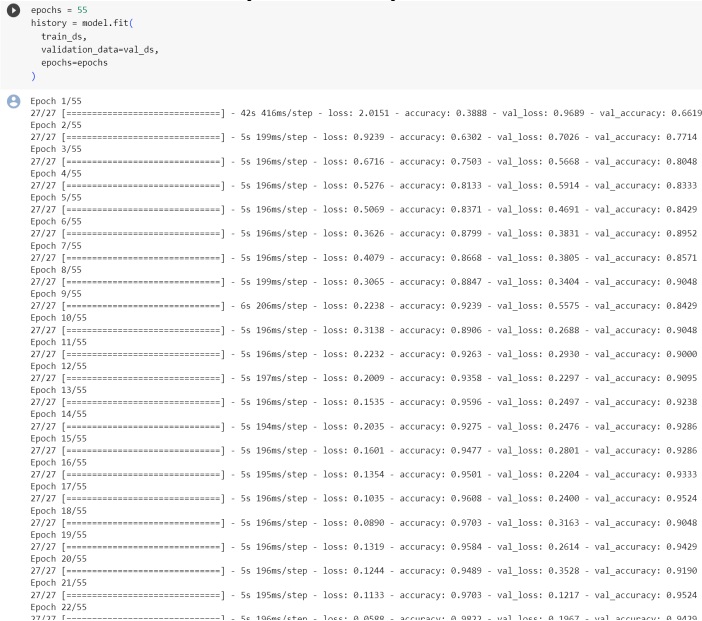
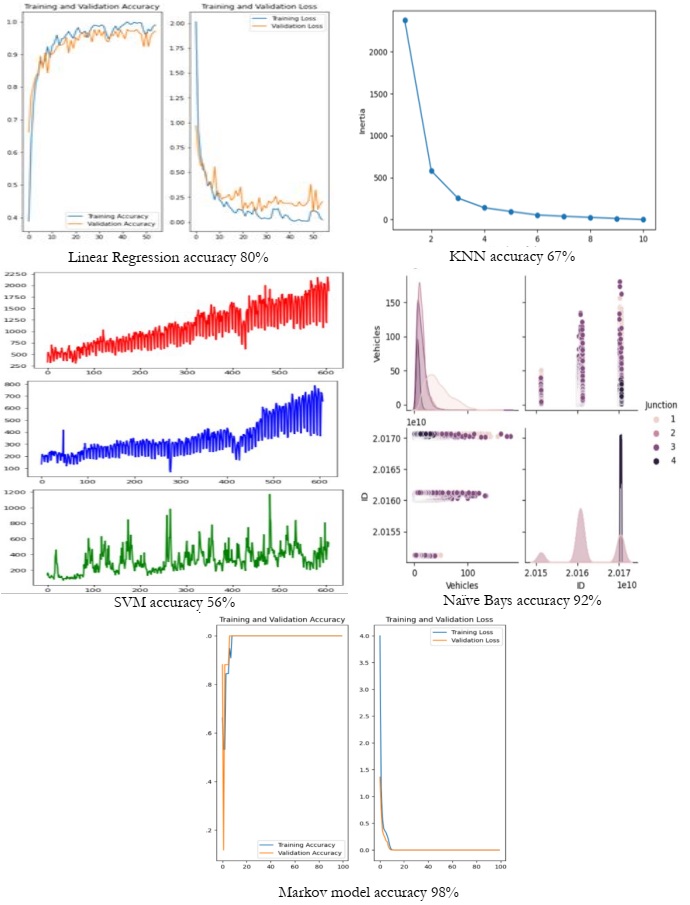
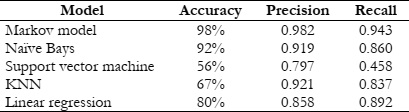
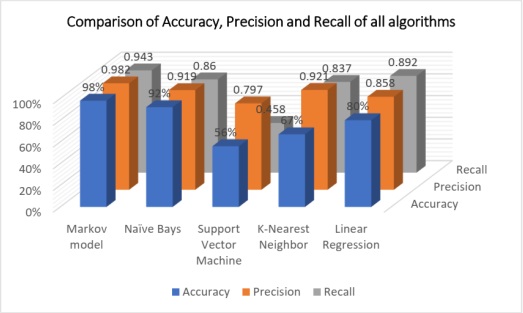
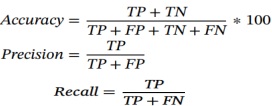Transportation of both people and goods is indispensable for human existence. The substantial rise in travel time can be attributed to the increasing global population and the imperative to enhance human well-being. The rapid escalation of technological progress has contributed directly to the concurrent rise in automobile ownership. Due to the rapid increase in the number of automobiles, it is of the uttermost importance to regulate the flow of vehicles. The implementation of vehicle management systems contributes to the optimization of both voyage durations and costs. In order to implement a vehicle management system that is both efficient and effective, it is necessary to have access to accurate and comprehensive background information. For the development of an efficient vehicular management system, the collection of data regarding traffic flow is essential. The objective of this study is to provide a comprehensive overview of the most recent deep learning techniques namely SVM, Naïve Bayes, KNN, Linear Regression and Markov based employed in the field of traffic density estimations in intelligent transportation systems. Only a few of the articles published on this topic have made substantial contributions to theorizing frameworks, whereas the overwhelming majority of contributions in this field are primarily concerned with practical applications. Deep learning algorithms have proven their ability to capture the nonlinear aspects of traffic flow prediction, and these systems have exhibited encouraging outcomes. Even though there are numerous benefits associated with the use of deep learning models for the prediction of individual traffic flow, it is essential to acknowledge the existence of a number of obvious disadvantages. Academics have abandoned the use of deep learning architectures in recent years in favor of hybrid and unsupervised methods. The present study investigates the numerous deep learning architectures currently employed in the field of traffic flow prediction, as well as the increasing prevalence of hybrid methods of analysis. The weather contributes to the unpredictability of road traffic. Potential factors occur in methodologies for estimating traffic road density; for instance, air humidity and the degree to which light, heavy, or moderate precipitation affects the average speed of vehicles are significant determinants. An additional critical factor is that if the data collection is reliant on sensor data, it could potentially impact the height of the structures. This is because intelligent transportation systems typically rely on vehicles that are connected to roadside units in close proximity. It has been found that the robustness of the comparison model develops, but subsequently begins a trend that leads it to decrease until it reaches a number that is considered to be crucial. The focus of this work is on groups or ensembles. In the context of classification, an ensemble is a composite model that is made up of a number of different classifiers
The research review delves into the integration of ML and Data Mining (DM) systems within the context of sustainable smart cities, particularly emphasizing their applications in intelligent transportation systems. A considerable amount of emphasis was placed on illustrative papers that elucidate on the application of ML techniques in the context of sustainable smart city networks, particularly with regard to traffic classification. Researchers investigating the topic of anomaly traffic categorization have conducted extensive research into a variety of feature selection and extraction strategies. Utilizing the aforementioned methodologies is standard practice for enhancing the dependability and usefulness of research studies conducted in this field. In order to classify internet traffic using techniques such as machine learning and data mining, both data and data features are required. Results are shown in Figure 7 as accuracy with each attribute as well as shown in Table 2.
These assessment indicators have been extensively employed in various studies for the purpose of acquiring and assessing the outcomes. Accuracy refers to the ratio of correctly identified traffic to the total tested traffic, specifically the proportion of accurately categorized real traffic from the whole pool of tested traffic. Precision is defined as the ratio of accurately categorized traffic, specifically, the ratio of correctly identified genuine traffic to all identified traffic. Recall refers to the ratio of accurately identified traffic (f) to the total amount of traffic. It represents the proportion of correctly identified true traffic in relation to the overall true traffic. As a result, it is necessary to provide a description of well-known and frequently utilized datasets that contain specific statistical information. This paper provides a comparison of algorithms with the detailed overview of the challenges and methods used in machine learning techniques for traffic classification. These methods and suggestions pertain to the classification of traffic. In the same manner, it is essential to provide a recommendation for each method, as recommendations are also pertinent to future activities. Nonetheless, this work presents a number of traffic classification proposals that are extremely valuable for future research. This employs the two feature engineering technologies, including spatial analysis and data for specific time durations and distances from which images of particular junctions and vehicles are generated. Additionally, an additional feature engineering technology is employed to gather data through sensors. The estimation of traffic density is contingent upon the utilization of these two feature engineering technologies. Additionally, this research conducted feature engineering by incorporating domain expertise in transportation.
[1] M. Satyanarayanan, “The emergence of edge computing,” Computer (Long. Beach. Calif)., vol. 50, pp. 30–39, 2017.
[2] T. H. Luan, L. Gao, Z. Li, Y. Xiang, G. Wei, and L. Sun, “Fog Computing: Focusing on Mobile Users at the Edge,” Feb. 2015, Accessed: Nov. 07, 2023. [Online]. Available: https://arxiv.org/abs/1502.01815v3
[3] S. Talari, M. Shafie-Khah, P. Siano, V. Loia, A. Tommasetti, and J. P. S. Catalão, “A Review of Smart Cities Based on the Internet of Things Concept,” Energies 2017, Vol. 10, Page 421, vol. 10, no. 4, p. 421, Mar. 2017, doi: 10.3390/EN10040421.
[4] J. Wu, C. Liu, W. Cui, and Y. Zhang, “Personalized Collaborative Filtering Recommendation Algorithm based on Linear Regression,” 2019 IEEE Int. Conf. Power Data Sci. ICPDS 2019, pp. 139–142, Nov. 2019, doi: 10.1109/ICPDS47662.2019.9017166.
[5] S. J. S and E. R. P, “LittleYOLO-SPP: A delicate real-time vehicle detection algorithm,” Optik (Stuttg)., vol. 225, p. 165818, Jan. 2021, doi: 10.1016/J.IJLEO.2020.165818.
[6] H. Beenish and M. Fahad, “5G a review on existing technologies,” 2019 2nd Int. Conf. Comput. Math. Eng. Technol. iCoMET 2019, Mar. 2019, doi: 10.1109/ICOMET.2019.8673407.
[7] G. Amato, F. Carrara, F. Falchi, C. Gennaro, C. Meghini, and C. Vairo, “Deep learning for decentralized parking lot occupancy detection,” Expert Syst. Appl., vol. 72, pp. 327–334, Apr. 2017, doi: 10.1016/J.ESWA.2016.10.055.
[8] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” Commun. ACM, vol. 60, no. 6, pp. 84–90, May 2017, doi: 10.1145/3065386.
[9] P. R. L. De Almeida, L. S. Oliveira, A. S. Britto, E. J. Silva, and A. L. Koerich, “PKLot – A robust dataset for parking lot classification,” Expert Syst. Appl., vol. 42, no. 11, pp. 4937–4949, Jul. 2015, doi: 10.1016/J.ESWA.2015.02.009.
[10] K. Gopalakrishnan, “Deep Learning in Data-Driven Pavement Image Analysis and Automated Distress Detection: A Review,” Data 2018, Vol. 3, Page 28, vol. 3, no. 3, p. 28, Jul. 2018, doi: 10.3390/DATA3030028.
[11] D. J. Daniels, “Ground Penetrating Radar,” Encycl. RF Microw. Eng., Apr. 2005, doi: 10.1002/0471654507.EME152.
[12] L. R. RABINER, “A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition,” Readings Speech Recognit., pp. 267–296, Jan. 1990, doi: 10.1016/B978-0-08-051584-7.50027-9.
[13] W. Liu, S. W. Kim, K. Marczuk, and M. H. Ang, “Vehicle motion intention reasoning using cooperative perception on urban road,” 2014 17th IEEE Int. Conf. Intell. Transp. Syst. ITSC 2014, pp. 424–430, Nov. 2014, doi: 10.1109/ITSC.2014.6957727.
[14] Y. Chen and Z. Li, “An Effective Approach of Vehicle Detection Using Deep Learning,” Comput. Intell. Neurosci., vol. 2022, 2022, doi: 10.1155/2022/2019257.
[15] Y. Gao, C. Zhou, J. Rong, Y. Wang, and S. Liu, “Short-Term Traffic Speed Forecasting Using a Deep Learning Method Based on Multitemporal Traffic Flow Volume,” IEEE Access, vol. 10, pp. 82384–82395, 2022, doi: 10.1109/ACCESS.2022.3195353.
[16] Y. Liu, S. Zhang, C. Zhang, and J. J. Q. Yu, “FedGRU: Privacy-preserving Traffic Flow Prediction via Federated Learning,” 2020 IEEE 23rd Int. Conf. Intell. Transp. Syst. ITSC 2020, Sep. 2020, doi: 10.1109/ITSC45102.2020.9294453.
[17] Z. Zheng and D. Su, “Short-term traffic volume forecasting: A k-nearest neighbor approach enhanced by constrained linearly sewing principle component algorithm,” Transp. Res. Part C Emerg. Technol., vol. 43, pp. 143–157, Jun. 2014, doi: 10.1016/J.TRC.2014.02.009.
[18] M. U. Khan, M. Hosseinzadeh, and A. Mosavi, “An Intersection-Based Routing Scheme Using Q-Learning in Vehicular Ad Hoc Networks for Traffic Management in the Intelligent Transportation System,” Math. 2022, Vol. 10, Page 3731, vol. 10, no. 20, p. 3731, Oct. 2022, doi: 10.3390/MATH10203731.
[19] A. K. Ikiriwatte, D. D. R. Perera, S. M. M. C. Samarakoon, D. M. W. C. B. Dissanayake, and P. L. Rupasignhe, “Traffic Density Estimation and Traffic Control using Convolutional Neural Network,” 2019 Int. Conf. Adv. Comput. ICAC 2019, pp. 323–328, Dec. 2019, doi: 10.1109/ICAC49085.2019.9103369.
[20] W. Zha et al., “A New Switched State Jump Observer for Traffic Density Estimation in Expressways Based on Hybrid-Dynamic-Traffic-Network-Model,” Sensors 2019, Vol. 19, Page 3822, vol. 19, no. 18, p. 3822, Sep. 2019, doi: 10.3390/S19183822.
[21] Y. Guo, Y. Chen, W. Li, and C. Zhang, “Distributed state-observer-based traffic density estimation of urban freeway network,” IEEE Conf. Intell. Transp. Syst. Proceedings, ITSC, vol. 2018-March, pp. 1177–1182, Jul. 2018, doi: 10.1109/ITSC.2017.8317628.
[22] A. K. Maurya, S. Das, S. Dey, and S. Nama, “Study on Speed and Time-headway Distributions on Two-lane Bidirectional Road in Heterogeneous Traffic Condition,” Transp. Res. Procedia, vol. 17, pp. 428–437, Jan. 2016, doi: 10.1016/J.TRPRO.2016.11.084.
[23] S. A. Nugroho, A. F. Taha, and C. Claudel, “Traffic density modeling and estimation on stretched highways: The case for lipschitz-based observers,” Proc. Am. Control Conf., vol. 2019-July, pp. 2658–2663, Jul. 2019, doi: 10.23919/ACC.2019.8814960.
[24] L. Fredianelli et al., “Traffic Flow Detection Using Camera Images and Machine Learning Methods in ITS for Noise Map and Action Plan Optimization,” Sensors, vol. 22, no. 5, p. 1929, Mar. 2022, doi: 10.3390/S22051929/S1.
[25] D. Mane, R. Bidwe, B. Zope, and N. Ranjan, “Traffic Density Classification for Multiclass Vehicles Using Customized Convolutional Neural Network for Smart City,” Lect. Notes Networks Syst., vol. 461, pp. 1015–1030, 2022, doi: 10.1007/978-981-19-2130-8_78/COVER.
[26] H. Beenish, T. Javid, M. Fahad, A. A. Siddiqui, G. Ahmed, and H. J. Syed, “A Novel Markov Model-Based Traffic Density Estimation Technique for Intelligent Transportation System,” Sensors 2023, Vol. 23, Page 768, vol. 23, no. 2, p. 768, Jan. 2023, doi: 10.3390/S23020768.