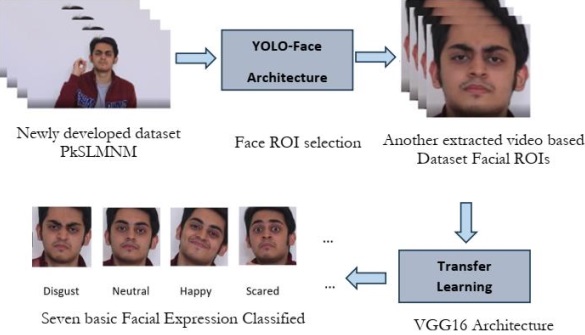
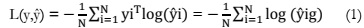Our newly developed dataset PkSLMNM is tested using the YOLO-Face
methodology to detect face ROIs. Different metrics are used to evaluate the performance like
precision, recall, F1-Score, accuracy, and current average loss. The values are 0.89, 0.96, 0.84,
and 90.89% for precision, recall, F1-Score, and accuracy respectively.
Figure 5 represents a loss graph with the current average loss of 0.34. This object
localization and classification loss classify the face region pixels into a binary class. Further,
we extracted or cropped the regions to make a new dataset of face expressions only derived
from PkSLMNM. We got another useful dataset for facial expression or emotion detection in
the spatio-temporal domain through this semantic segmentation in videos. Further, figure 6
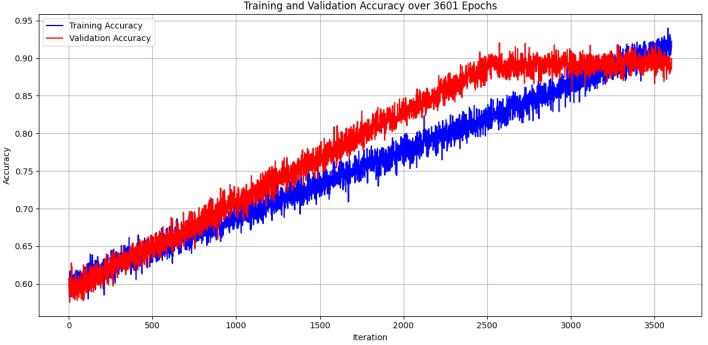
depicts the accuracy graph of training and validation of the proposed model, both the training
and validation accuracy lines converge and stabilize at a high degree of accuracy, showing that
our model is learning effectively without overfitting.
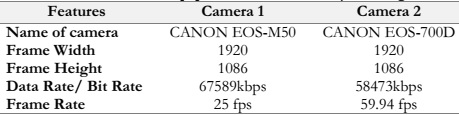
We used the PkSLMNM dataset to recognize both manual and non-manual motions
at the same time. This dataset contains video clips shot with an HD camera in.MP4 format,
capturing a variety of facial emotions as well as hand movements. To guarantee that the data
was suitable for classification, we went through a preprocessing phase in which we converted
the video clips into frames and methodically removed any noise that could potentially interfere
with the classification process. Each frame has a uniform resolution of 1920x1086 pixels, and
all frame boundaries are properly labeled with the seven basic emotions corresponding classes.
We used the You Only Look Once-Face (YOLO-Face) architecture to precisely
recognize faces within the dataset and identify them as Regions of Interest (ROIs) to validate
it. YOLO-Face is a hybrid technique that combines the darknet-19 architecture with a residual
network composed of 53 convolutional neural network layers. To get high-quality facial
characteristics, we raised the number of layers in the residual blocks by 4x and 8x, respectively,
resulting in a network known as a deeper DarkNet. YOLO-Face, in particular, converts the
classification challenge from a multi-class problem to a binary classification task, concentrating
simply on the presence or absence of a face. Furthermore, YOLO-Face excels at detecting
faces at three different scales, improving the accuracy and robustness of the system.
Compiling a Kera’s model using categorical cross entropy as the loss function and
Stochastic Gradient Descent (SGD) as the optimizer. The learning rate is set to 0.0001, and
momentum is configured to be 0.9. Additionally, you've included several custom metrics for
evaluation, such as accuracy, F1 score (f1_m), precision (precision_m), recall (recall_m), and
AUC (Area Under the Curve).
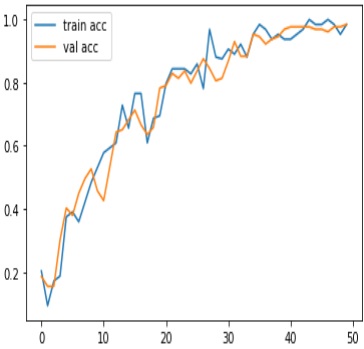
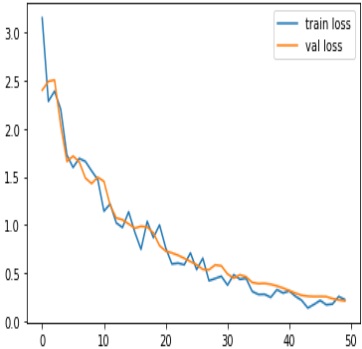
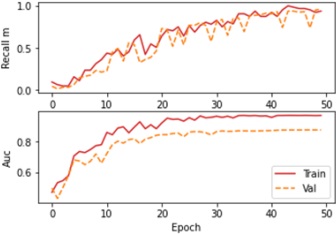
The model has achieved a low loss of 0.2153, indicating that it is performing well in
minimizing its prediction errors. The accuracy is high at 98.45%, suggesting that the majority
of predictions are correct. The F1 score is 0.9777, which is a good balance between precision
and recall. Precision is high at 99.35%, indicating a low rate of false positives, while recall is
96.25%, showing a good ability to capture true positives. The AUC (Area Under the Curve) is
0.8755, which is commonly used to evaluate the performance of a binary classification model.
Overall, these metrics suggest that the model is performing very well on the task it was trained
for. Figures 7, 8, 9, and 10 show the graphical representations of the results. Discussion:
The PkSLMNM dataset, which focuses on Pakistan Sign Language (PSL), presents a
unique resource for the study and development of Sign Language Recognition. In the
discussion below, we will explore various aspects and comparisons related to this dataset.
PkSLMNM stands out as it primarily focuses on dynamic hand movements, setting it
apart from previous datasets that mainly concentrated on static sign language signs represented
as still images. This emphasizes the importance of capturing the temporal aspect of Sign
Language, making it more applicable to real-world communication scenarios.
The dataset includes both manual and non-manual modalities, which is essential for
comprehensive sign language recognition. Manual modalities encompass hand and arm
movements, while non-manual modalities involve facial expressions and other upper-body
motions. This comprehensive approach reflects the complexity of sign language
communication.
PkSLMNM offers a significant lexicon of sign language gestures, enabling a broader
range of signs to be recognized and analyzed. A large lexicon is crucial for developing practical
sign language recognition systems, as it covers a wider range of vocabulary and expressions.
The dataset is notable for its high-quality recordings, ensuring that the data is reliable
and accurate for research and development purposes. High-quality recordings are essential for
training and evaluating recognition systems, as they reduce noise and improve model
performance.
PkSLMNM incorporates a unique syntactic trait that allows for the recognition of
dynamic hand motions. This feature contributes to the dataset's versatility and adaptability, as
it accommodates the complexities of sign language syntax and structure.
While previous datasets focused on controlled sign activities, PkSLMNM strives to
capture real-world sign language usage. This is critical for developing recognition systems that
can operate effectively in everyday communication scenarios.
PkSLMNM represents a valuable resource for research in sign language recognition,
offering both robustness and domain-specificity. Robustness is essential for ensuring that
recognition systems can handle various environmental conditions and signing styles, while
domain-specificity focuses on the unique characteristics of PSL.
The dataset includes emotional representations in sign language, allowing for the
recognition of emotional cues in sign communication. This is a valuable addition as emotions
play a significant role in sign language expression.
When compared to other sign language datasets, PkSLMNM stands out for its
dynamic nature, comprehensive coverage of manual and non-manual modalities, and large
lexicon. It complements existing datasets by addressing the need for real-world sign language
recognition.
PkSLMNM's features and characteristics create a foundation for the development of
advanced sign language recognition systems. Researchers and developers can leverage this
dataset to enhance the accuracy and applicability of sign language recognition technology.
In summary, the PkSLMNM dataset represents a significant advancement in the field of
sign language recognition, offering a unique combination of dynamic gestures, comprehensive
modalities, and a large lexicon. Its focus on real-world sign language usage, robustness, and
emotional representations makes it a valuable resource for researchers and developers in the
domain of sign language technology.
[1] M. Al-Qurishi, T. Khalid, and R. Souissi, “Deep Learning for Sign Language Recognition:
Current Techniques, Benchmarks, and Open Issues,” IEEE Access, vol. 9, pp. 126917-126951,
2021.
[2] J. Zheng, Y. Chen, C. Wu, X. Shi, and S. M. Kamal, “Enhancing Neural Sign Language
Translation by Highlighting the Facial Expression Information,” Neurocomputing, vol. 464, pp.
462–472, 2021.
[3] A. Singh, S. K. Singh, and A. Mittal, “A Review on Dataset Acquisition Techniques in Gesture
Recognition from Indian Sign Language,” in Advances in Data Computing, Communication and
Security, Springer, vol. 106, pp. 305–313, 2021.
[4] S. Sharma and S. Singh, “Vision-based hand gesture recognition using deep learning for the
interpretation of sign language,” Expert Systems and Applications, vol. 182, p. 115657, 2021.
[5] I. Rodríguez-Moreno, J. M. Martínez-Otzeta, I. Goienetxea, and B. Sierra, “Sign Language
Recognition by means of Common Spatial Patterns,” in 2021 The 5th International Conference
on Machine Learning and Soft Computing, Da Nang Viet Nam, 2021, pp. 96–102.
[6] H. Zahid, M. Rashid, S. Hussain, F. Azim, S. A. Syed, and A. Saad, “Recognition of Urdu Sign
Language: A Systematic Review of the Machine Learning Classification,” PeerJ Computer Science,
vol. 8, p. e883, 2022.
[7] “Deaf Reach Schools and Training Centers in Pakistan.” https://www.deafreach.com/
[Online] (accessed May 19, 2022).
[8] “PSL.” https://psl.org.pk/ [Online] (accessed May 19, 2022).
[9] A. Imran, A. Razzaq, I. A. Baig, A. Hussain, S. Shahid, and T.-U. Rehman, “Dataset of Pakistan
Sign Language and Automatic Recognition of Hand Configuration of Urdu Alphabet through
Machine Learning,” Data in Brief, vol. 36, p. 107021, Jun. 2021, doi: 10.1016/j.dib.2021.107021.
[10] “Pakistan Sign Language Dataset - Open Data Pakistan.” [Online]
https://opendata.com.pk/dataset/pakistan-sign-language-dataset (accessed May 19, 2022).
[11] S. Javaid, S. Rizvi, M. T. Ubaid, A. Darboe and S. M. Mayo, “Interpretation of Expressions
through Hand Signs Using Deep Learning Techniques”, International Journal of Innovations in
Science and Technology, vol. 4, no. 2, pp. 596-611, 2022.
[12] S. Javaid and S. Rizvi, "A novel action transformer network for hybrid multimodal sign
language recognition," Computers, Materials & Continua, vol. 74, no.1, pp. 523–537, 2023.
[13] R. Gavrilescu, C. Zet, C. Foșalău, M. Skoczylas, and D. Cotovanu, “Faster R-CNN: An
Approach to Real-Time Object Detection,” in 2018 International Conference and Exposition on
Electrical and Power Engineering (EPE), Iasi, Romania, 2018, pp. 0165–0168.
[14] J. Redmon and A. Farhadi, “YOLOv3: An Incremental Improvement,” ArXiv Prepr.
ArXiv180402767, 2018.
[15] W. Chen, H. Huang, S. Peng, C. Zhou, and C. Zhang, “YOLO-Face: A Real-Time Face
Detector,” The Visual Computer, vol. 37, no. 4, pp. 805–813, 2021.
[16] S.-W. Kim, H.-K. Kook, J.-Y. Sun, M.-C. Kang, and S.-J. Ko, “Parallel Feature Pyramid
Network for Object Detection,” in Proceedings of the European Conference on Computer Vision
(ECCV), Munich, Germany, 2018, pp. 234–250.
[17] W. I. D. Mining, “Data mining: Concepts and techniques,” Morgan Kaufinann, vol. 10, pp.
559–569, 2006.
[18] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A Unified Embedding for Face
Recognition and Clustering,” in Proceedings of the IEEE conference on computer vision and
pattern recognition, Boston, MA, USA, 2015, pp. 815–823.
[19] A. Jain, K. Nandakumar, and A. Ross, “Score Normalization in Multimodal Biometric
Systems,” Pattern Recognition, vol. 38, no. 12, pp. 2270–2285, 2005.
[20] Javaid, Sameena and Rizvi, Safdar. ‘Manual and Non-manual Sign Language Recognition
Framework Using Hybrid Deep Learning Techniques’. 1 Jan. 2023: 3823 – 3833.
[21] H. Mohabeer, K. S. Soyjaudah, and N. Pavaday, “Enhancing The Performance Of Neural
Network Classifiers Using Selected Biometric Features”, SENSORCOMM 2011: The Fifth
International Conference on Sensor Technologies and Applications, Saint Laurent du Var, France,
2011.
[22] S. Khan, H. Rahmani, S. A. A. Shah, and M. Bennamoun, “A Guide to Convolutional Neural
Networks for Computer Vision,” Synthesis Lectures on Computer Vision, vol. 8, no. 1, pp. 1–
207, 2018.
[23] E. Kremic and A. Subasi, “Performance of Random Forest and SVM in Face Recognition.”
Int Arab Journal of Information Technology, vol. 13, no. 2, pp. 287–293, 2016.
[24] E. Setiawan and A. Muttaqin, “Implementation of k-Nearest Neighbors Face Recognition on
Low-Power Processor,” Telecommunication Computing Electronics and Control, vol. 13, no. 3,
pp. 949–954, 2015.
[25] M. T. Ubaid, A. Kiran, M. T. Raja, U. A. Asim, A. Darboe and M. A. Arshed, "Automatic
Helmet Detection using EfficientDet," 2021 International Conference on Innovative Computing
(ICIC), Lahore, Pakistan, 2021, pp. 1-9, doi: 10.1109/ICIC53490.2021.9693093.
[26] M. A. Arshed, H. Ghassan, M. Hussain, M. Hassan, A. Kanwal, and R. Fayyaz, “A Light
Weight Deep Learning Model for Real World Plant Identification,” 2022 2nd Int. Conf. Distrib.
Comput. High Perform. Comput. DCHPC 2022, pp. 40–45, 2022, doi:
10.1109/DCHPC55044.2022.9731841.
[27] M. T. Ubaid, M. Z. Khan, M. Rumaan, M. A. Arshed, M. U. G. Khan and A. Darboe,
"COVID-19 SOP’s Violations Detection in Terms of Face Mask Using Deep Learning," 2021
International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 2021, pp. 1-8, doi:
10.1109/ICIC53490.2021.9692999.
[28] M. A. Arshed, H. Ghassan, M. Hussain, M. Hassan, A. Kanwal and R. Fayyaz, "A Light Weight
Deep Learning Model for Real World Plant Identification," 2022 Second International Conference
on Distributed Computing and High Performance Computing (DCHPC), Qom, Iran, Islamic
Republic of, 2022, pp. 40-45, doi: 10.1109/DCHPC55044.2022.9731841.
[29] M. A. Arshed, A. Shahzad, K. Arshad, D. Karim, S. Mumtaz, and M. Tanveer, “Multiclass
Brain Tumor Classification from MRI Images using Pre-Trained CNN Model”, VFAST trans.
softw. eng., vol. 10, no. 4, pp. 22–28, Nov. 2022.
[30] A. Shahzad, M. A. Arshed, F. Liaquat, M. Tanveer, M. Hussain, and R. Alamdar, “Pneumonia
Classification from Chest X-ray Images Using Pre-Trained Network Architectures”, VAWKUM
trans. comput. sci., vol. 10, no. 2, pp. 34–44, Dec. 2022.
[31] H. Younis, Muhammad Asad Arshed, Fawad ul Hassan, Maryam Khurshid, and Hadia
Ghassan, “Tomato Disease Classification using Fine-Tuned Convolutional Neural
Network”, IJIST, vol. 4, no. 1, pp. 123–134, Feb. 2022.
[32] M. Mubeen, M. A. Arshed, and H. A. Rehman, “DeepFireNet - A Light-Weight Neural
Network for Fire-Smoke Detection,” Commun. Comput. Inf. Sci., vol. 1616 CCIS, pp. 171–181,
2022, doi: 10.1007/978-3-031-10525-8_14/COVER.
[33] Q. Zhu, Z. He, T. Zhang, and W. Cui, “Improving Classification Performance of Softmax
Loss Function based on Scalable Batch-Normalization,” Applied Sciences, vol. 10, no. 8, p. 2950,
2020.