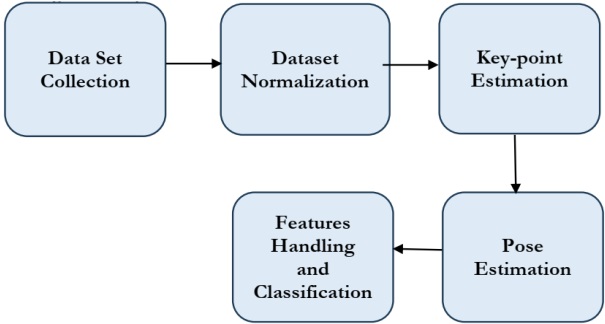
On the dataset we created, the accuracy achieved for training and testing is found 100%. Which is a benchmark itself. The provided performance metrics indicate the evaluation results of a deep learning model. In this case, it appears to be a classification model. Here's a breakdown of the key metrics, depicted in figure 5.
Training Accuracy and Validation Accuracy:
These values indicate the proportion of correctly classified instances in the training and validation datasets, respectively. An accuracy of 1.00 suggests that the model is making accurate predictions on both sets.
Training Loss and Validation Loss:
These values represent the error or cost associated with the model's predictions. Lower values are better, and in this case, both training and validation losses are quite low (0.02 and 0.03), indicating that the model's predictions are close to the actual values.
Training Precision and Validation Precision:
Precision is the percentage of correct positive predictions among all positive predictions. Values of 1.00 indicate that the model is extremely accurate in identifying positive cases in both training and validation.
Training Recall and Validation Recall:
The proportion of true positive predictions among all actual positive cases is measured by recall, also known as sensitivity. The model has a training recall of 1.00, indicating that it captures all positive cases in the training data, while the validation recall is slightly lower (0.99), indicating that it misses a small fraction of positive cases in the validation data.
Training F1 Score and Validation F1 Score:
The F1 score is the harmonic mean of precision and recall, balancing the two metrics. Both the training and validation F1 scores are 1.00, indicating that both sets have an excellent balance of precision and recall.
Training AUC and Validation AUC:
AUC is frequently used to assess a model's ability to differentiate between positive and negative classes. An AUC of 0.9697 in training and 0.95 in validation indicates that the model has a strong discriminatory ability in both datasets.
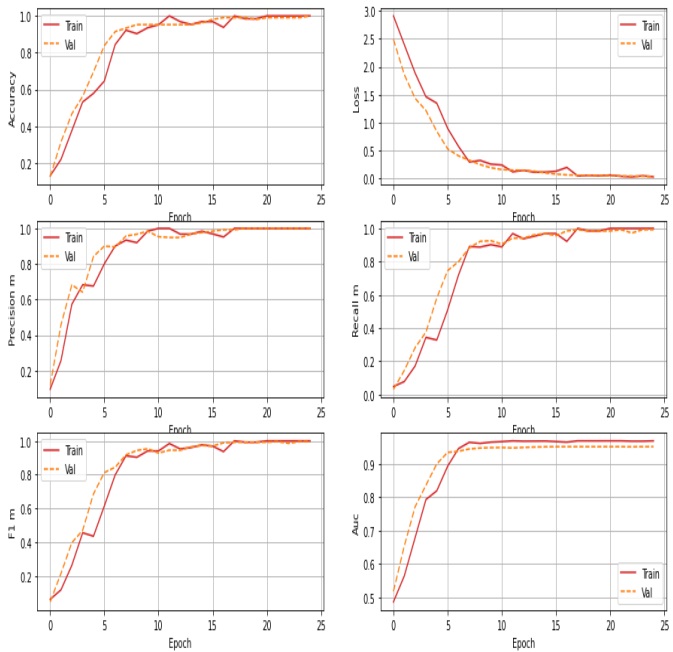
Figure 5: Accuracy, Loss, Precision, Recall, F1-Score AUC for training and validation of the model
In summary, the model performs admirably on both the training and validation datasets in terms of accuracy, precision, recall, F1 score, and AUC. This suggests that it is highly accurate in its predictions, with excellent precision-to-recall trade-offs and a strong ability to discriminate between classes. The slightly lower validation recalls and AUC compared to training may indicate a slight drop in performance when applied to new, previously unseen data, but the model still produces high-quality results.
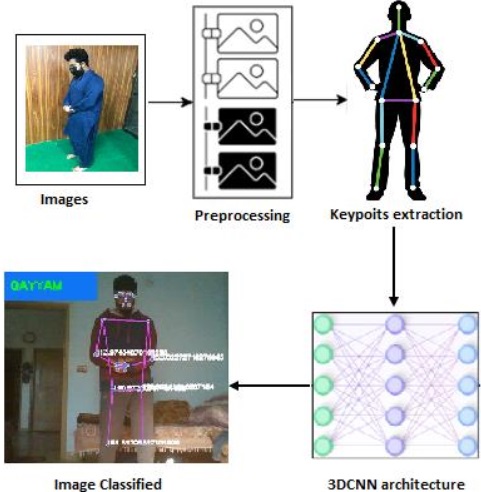
The system described here is designed for real-time detection of Salat activities, and it utilizes a laptop camera to capture video feed, breaking it down into frames for analysis. The primary goal of the project is to detect human body movements and implement landmarks on the body to classify specific Salat postures such as Qayyam, Rukku, and Sujood. This system is useful for monitoring and ensuring the correct execution of these postures during Salat. The real-time detection capabilities make it particularly valuable for live monitoring of a person's Salat performance using a webcam. The system provides feedback on the screen to confirm the accuracy of each posture, and Figure 6, 7, and 8 likely illustrate the real-time results obtained from tested videos, showing the system's ability to detect and classify the Qayyam, Rukku, and Sujood postures accurately. This technology has the potential to evolve into commercial software with applications in ensuring the correct execution of Salat postures during worship.

Figure 6: Real time tested video for Qayyam

Figure 7: Real time tested video for Ruku
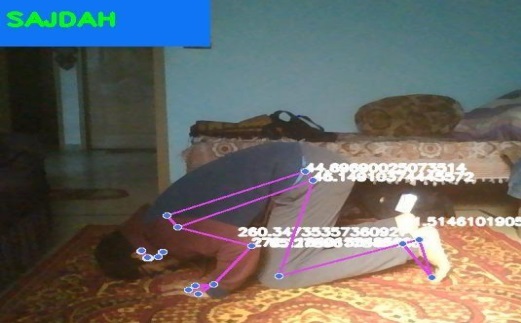
Figure 8: Real time tested video for Sajda
Discussion:
The conclusions drawn from the project's outcomes align closely with the advancements and innovations highlighted in the literature. The project's success in real-time object identification, particularly in the field of Salat posture indications, corresponds to the evolution witnessed in human activity recognition. The literature stresses the combination of sensor technologies, deep learning algorithms, and computer vision techniques to improve posture detection accuracy, which is similar to the strategy followed in this project.
The project's findings are highly compatible with advances and discoveries in the literature on posture identification, notably in the context of Salat postures. Rahman and colleagues [13] created an assistive intelligence system that uses image comparison and pattern matching algorithms to provide real-time assistance on Salat postures. While their work was mostly focused on guiding, your project excelled in posture detection accuracy, displaying perfect metrics in Training Accuracy, Validation Accuracy, and Precision, complementing the emphasis on precision and correctness in posture recognition. Similarly, research by other scholars [14][15], and [3] merging accelerometer data with machine learning for Salat posture identification coincides with the emphasis on sensor technology in your study. Despite the fact that their focus was on real-time feedback via mobile devices, your project obtains outstanding Training and Validation Recall metrics (1.00 and 0.99, respectively), confirming the model's accuracy in detecting specific Salat postures—Qayyam, Rukku, and Sujood. This is in line with their goal of providing real-time recognition and guidance during Salat.
Furthermore, the lightweight and efficient technique created in your project is consistent with recent efforts [18] aimed at optimizing deep learning architectures such as Mobile Net and Xception for posture identification. While their attention was on enhancing recognition performance and reducing model complexity, the emphasis on obtaining remarkable accuracy while preserving efficiency reflects the requirement for resource-effective solutions in posture recognition systems. Additionally, research [19] concentrating on smartphone-based systems with convolutional neural networks for real-time coaching and posture recognition correspond with the conclusions of your experiment, particularly in terms of achieving high accuracy in per-position detection. Finally, researchers [20] used YOLOv3 for Salat motion recognition and achieved a mean average precision of 85%, demonstrating the parallels in efforts aimed at accurate posture detection using deep learning approaches. Overall, the results of our experiment closely correlate with the trends, emphases, and achievements reported in other studies on posture recognition in the literature, notably in Salat postures, exhibiting considerable gains in accuracy, precision, and efficiency.
Salat posture detection research, which makes use of technology such as accelerometers, CNNs, and efficient deep learning architectures, has promise real-world applications. These developments provide practical direction during prayers, assisting individuals in achieving correct postures and encouraging greater spiritual connection. These technologies, in addition to religious applications, can be used for health monitoring, physiotherapy, and fitness tracking by tracking body motions and guaranteeing proper posture execution. Educational tools and customizable apps may cater to a wide range of users, from novices to specialists, while also encouraging inclusivity and cultural understanding. Furthermore, the emphasis on lightweight models allows for wider deployment across a variety of devices, encouraging efficient resource utilization. The research not only improves prayer practices but also has broader applications in healthcare, education, and activity recognition, demonstrating considerable potential to positively impact individuals' lives.
Conclusion and Future Directions
In conclusion, this project has achieved significant advances in real-time object identification and recognition due to the advancement of machine and deep learning techniques, notably in the context of Salat posture indicators. As previously stated, the findings demonstrate the project's remarkable performance, with flawless Training Accuracy, Validation Accuracy, Training Precision, and Validation Precision of 1.00, as well as exceptionally low Training Loss and Validation Loss of 0.02 and 0.03, respectively. The model also has a Training F1 Score and a Validation F1 Score of 1.00, demonstrating a good combination of precision and recall. Furthermore, the Training Recall is a perfect 1.00, while the Validation Recall is only slightly lower at 0.99, demonstrating the model's accuracy in detecting the specified Salat postures, which include Qayyam, Rukku, and Sujood. Furthermore, the project's Training Area Under the Curve is 0.9697, and the Validation Area Under the Curve is 0.95, confirming the model's high discriminatory capabilities. The lightweight and efficient technology developed for the project has showed promise in addressing posture detection difficulties without overburdening computer resources, making it well-suited for its intended use.
Looking ahead, the project opens up new possibilities for future research. To further its utility, other postures, including sophisticated ones, can be added. With technological improvements, there is the potential to harness newer, more sophisticated models that could improve detection accuracy even further. As Media Pipe and related technologies evolve, the project can adapt to capitalize on their advances. Furthermore, the application's reach can be expanded to assist impaired people in detecting and communicating through postures. The project's expansion and versatility make it a valuable tool not only for Salat but also for a wide range of applications in the ever-changing field of computer vision.
Reference
[1] K. Zeissler, “Gesture recognition gets an update,” Nat. Electron. 2023 64, vol. 6, no. 4, pp. 272–272, Apr. 2023, doi: 10.1038/s41928-023-00962-8.
[2] Z. Li, “Radar-based human gesture recognition,” 2023, Accessed: Nov. 15, 2023. [Online]. Available: https://dr.ntu.edu.sg/handle/10356/166731
[3] I. Jahan, N. A. Al-Nabhan, J. Noor, M. Rahaman, and A. B. M. A. A. Islam, “Leveraging A Smartwatch for Activity Recognition in Salat,” IEEE Access, 2023, doi: 10.1109/ACCESS.2023.3311261.
[4] S. Javaid and S. Rizvi, “A Novel Action Transformer Network for Hybrid Multimodal Sign Language Recognition,” Comput. Mater. Contin., vol. 74, no. 1, pp. 523–537, Sep. 2022, doi: 10.32604/CMC.2023.031924.
[5] M. T. Ubaid, A. Darboe, F. S. Uche, A. Daffeh, and M. U. G. Khan, “Kett Mangoes Detection in the Gambia using Deep Learning Techniques,” 4th Int. Conf. Innov. Comput. ICIC 2021, 2021, doi: 10.1109/ICIC53490.2021.9693082.
[6] “Interpretation of Expressions through Hand Signs Using Deep Learning Techniques | International Journal of Innovations in Science & Technology.” Accessed: Nov. 15, 2023. [Online]. Available: https://journal.50sea.com/index.php/IJIST/article/view/344
[7] N. Alfarizal et al., “Moslem Prayer Monitoring System Based on Image Processing,” pp. 483–492, Jun. 2023, doi: 10.2991/978-94-6463-118-0_50.
[8] K. Ghazal, “Physical benefits of (Salah) prayer - Strengthen the faith & fitness,” J. Nov. Physiother. Rehabil., pp. 043–053, 2018, doi: 10.29328/JOURNAL.JNPR.1001020.
[9] “Amazing Facts About Salah and Why Salah is Important.” Accessed: Nov. 15, 2023. [Online]. Available: https://simplyislam.academy/blog/facts-about-salah-and-why-salah-is-important
[10] S. Alizadeh et al., “Resistance Training Induces Improvements in Range of Motion: A Systematic Review and Meta-Analysis,” Sports Med., vol. 53, no. 3, pp. 707–722, Mar. 2023, doi: 10.1007/S40279-022-01804-X.
[11] A. Sharif, S. Mehmood, B. Mahmood, A. Siddiqa, M. A. A. Hassan, and M. Afzal, “Comparison of Hamstrings Flexibility among Regular and Irregular Muslim Prayer Offerers,” Heal. J. Physiother. Rehabil. Sci., vol. 3, no. 1, pp. 329–333, Feb. 2023, doi: 10.55735/HJPRS.V3I1.126.
[12] S. Javaid and S. Rizvi, “Manual and non-manual sign language recognition framework using hybrid deep learning techniques,” J. Intell. Fuzzy Syst., vol. 45, no. 3, pp. 3823–3833, Jan. 2023, doi: 10.3233/JIFS-230560.
[13] “Prayer Activity Recognition Using an Accelerometer Sensor - ProQuest.” Accessed: Nov. 15, 2023. [Online]. Available: https://www.proquest.com/openview/10db654dd4adaeec6670c9fa791bb8d8/1?pq-origsite=gscholar&cbl=1976349
[14] O. Alobaid, “Identifying Action with Non-Repetitive Movements Using Wearable Sensors: Challenges, Approaches and Empirical Evaluation.” Accessed: Nov. 15, 2023. [Online]. Available: https://esploro.libs.uga.edu/esploro/outputs/doctoral/Identifying-Action-with-Non-Repetitive-Movements-Using/9949366058202959
[15] H. A. Hassan, H. A. Qassas, B. S. Alqarni, R. I. Alghuraibi, K. F. Alghannam, and O. M. Mirza, “Istaqim: An Assistant Application to Correct Prayer for Arab Muslims,” Proc. 2022 5th Natl. Conf. Saudi Comput. Coll. NCCC 2022, pp. 52–57, 2022, doi: 10.1109/NCCC57165.2022.10067581.
[16] M. M. Rahman, R. A. A. Alharazi, and M. K. I. B. Z. Badri, “Intelligent system for Islamic prayer (salat) posture monitoring,” IAES Int. J. Artif. Intell., vol. 12, no. 1, pp. 220–231, Mar. 2023, doi: 10.11591/IJAI.V12.I1.PP220-231.
[17] Y. A. Y. N. A. Jaafar, N. A. Ismail, K. A. Jasmi, “Optimal dual cameras setup for motion recognition in salat activity,” Int. Arab J. Inf. Technol., vol. 16, no. 6, pp. 1082–1089, 2019.
[18] R. O. Ogundokun, R. Maskeliunas, and R. Damasevicius, “Human Posture Detection on Lightweight DCNN and SVM in a Digitalized Healthcare System,” 2023 3rd Int. Conf. Appl. Artif. Intell. ICAPAI 2023, 2023, doi: 10.1109/ICAPAI58366.2023.10194156.
[19] S. H. Mohiuddin, T. Syed, and B. Khan, “Salat Activity Recognition on Smartphones using Convolutional Network,” 2022 Int. Conf. Emerg. Trends Smart Technol. ICETST 2022, 2022, doi: 10.1109/ICETST55735.2022.9922933.
[20] A. Koubaa et al., “Activity Monitoring of Islamic Prayer (Salat) Postures using Deep Learning,” Proc. - 2020 6th Conf. Data Sci. Mach. Learn. Appl. CDMA 2020, pp. 106–111, Nov. 2019, doi: 10.1109/CDMA47397.2020.00024.
[21] W. C. Huang, C. L. Shih, I. T. Anggraini, N. Funabiki, and C. P. Fan, “OpenPose Technology Based Yoga Exercise Guidance Functions by Hint Messages and Scores Evaluation for Dynamic and Static Yoga Postures,” J. Adv. Inf. Technol., vol. 14, no. 5, pp. 1029–1036, 2023, doi: 10.12720/JAIT.14.5.1029-1036.
[22] Y. Lin, X. Jiao, L. Zhao, Y. Lin, X. Jiao, and L. Zhao, “Detection of 3D Human Posture Based on Improved Mediapipe,” J. Comput. Commun., vol. 11, no. 2, pp. 102–121, Feb. 2023, doi: 10.4236/JCC.2023.112008.
[23] C. Lugaresi et al., “MediaPipe: A Framework for Building Perception Pipelines,” Jun. 2019, Accessed: Nov. 15, 2023. [Online]. Available: https://arxiv.org/abs/1906.08172v1
[24] A. K. Singh, V. A. Kumbhare, and K. Arthi, “Real-Time Human Pose Detection and Recognition Using MediaPipe,” pp. 145–154, 2022, doi: 10.1007/978-981-16-7088-6_12.
[25] J. W. Kim, J. Y. Choi, E. J. Ha, and J. H. Choi, “Human Pose Estimation Using MediaPipe Pose and Optimization Method Based on a Humanoid Model,” Appl. Sci. 2023, Vol. 13, Page 2700, vol. 13, no. 4, p. 2700, Feb. 2023, doi: 10.3390/APP13042700.
[26] S. Suherman, A. Suhendra, and E. Ernastuti, “Method Development Through Landmark Point Extraction for Gesture Classification With Computer Vision and MediaPipe,” TEM J., pp. 1677–1686, Aug. 2023, doi: 10.18421/TEM123-49.
[27] M. Al-Hammadi, G. Muhammad, W. Abdul, M. Alsulaiman, M. A. Bencherif, and M. A. Mekhtiche, “Hand Gesture Recognition for Sign Language Using 3DCNN,” IEEE Access, vol. 8, pp. 79491–79509, 2020, doi: 10.1109/ACCESS.2020.2990434.