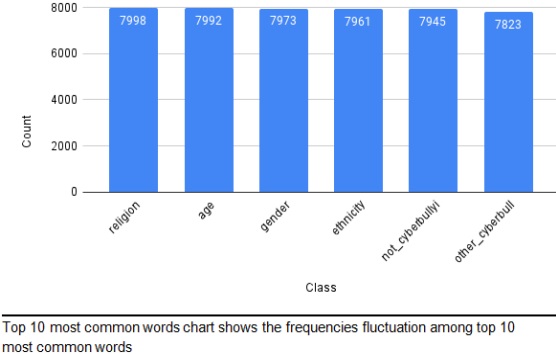
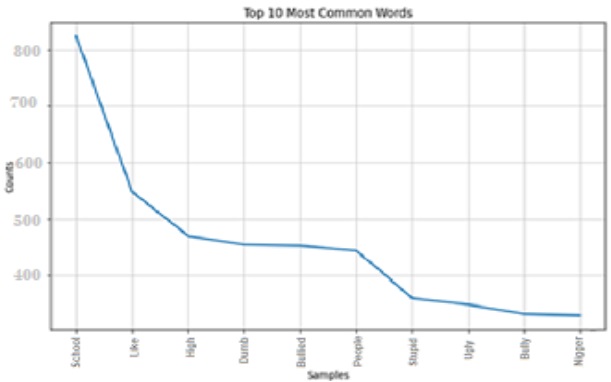
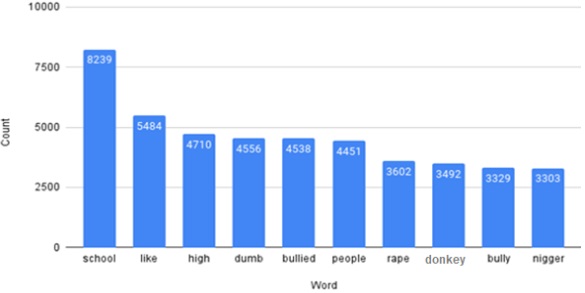
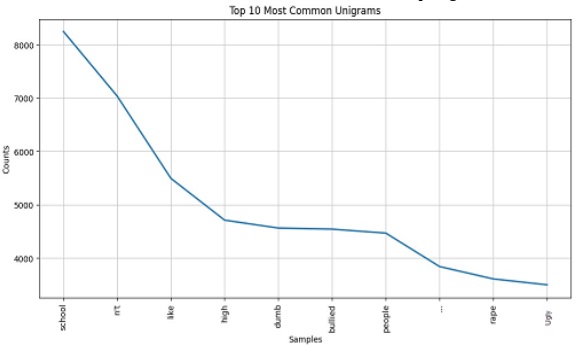
The classifier's performance was evaluated by comparing its testing results with other established machine learning models considered as industry standards. The evaluation involved diverse input data scenarios, validating the prediction results of cyberbullying with accuracy scores of 83.26%, precision scores of 83.66%, and recall scores of 83.05% shown in Figure 7.
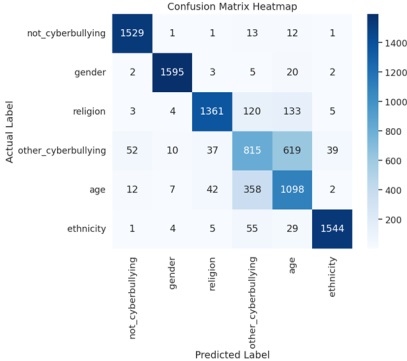
Confusion metrics were used in the evaluation process to assess the model's performance shown in Figure 8. A confusion matrix is a matrix representation that summarizes the predictions made by a model. It displays the number of correct and incorrect predictions for each class, aiding in the understanding of which classes the model is confusing with other classes. This matrix provides a clear breakdown of how well the model performs for each class and helps identify specific instances where the model's predictions might be inaccurate or confused with similar classes.
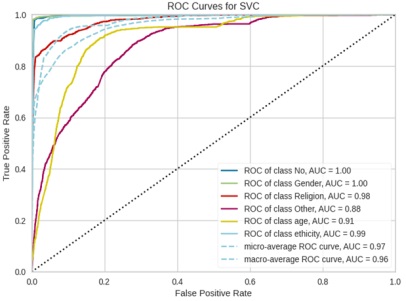
The Receiver Operating Characteristic Curve (ROC curve) displays an algorithm for classification performs across all categorization levels. Two parameters are shown on this curve in Figure 9: True Positive Rate and False positive rate. Classification algorithms are employed in machine learning techniques to obtain a prediction on the input stream in order
to classify items for further investigation. In numerous instances, the susceptibility or true positive rate (detection/recognition rate) of the classification algorithms is just as crucial as the accuracy of the methods.
[1] A. Ali and A. M. Syed, “Cyberbullying Detection using Machine Learning,” Pakistan J.
Eng. Technol., vol. 3, no. 2, pp. 45–50, 2020, doi: 10.51846/VOL3ISS2PP45-50.
[2] C. Sharma, R. Ramakrishnan, A. Pendse, P. Chimurkar, and K. T. Talele, “CYBER- BULLYING DETECTION VIA TEXT MINING AND MACHINE LEARNING,” 2021 12th Int. Conf. Comput. Commun. Netw. Technol. ICCCNT 2021, 2021, doi: 10.1109/ICCCNT51525.2021.9579625.
[3] Q. Huang, V. K. Singh, and P. K. Atrey, “Cyber bullying detection using social and textual analysis,” SAM 2014 - Proc. 3rd Int. Work. Soc. Multimedia, Work. MM 2014, pp. 3–6, Nov. 2014, doi: 10.1145/2661126.2661133.
[4] N. Singh and S. K. Sharma, “Review of Machine Learning methods for Identification of Cyberbullying in Social Media,” Proc. - Int. Conf. Artif. Intell. Smart Syst. ICAIS 2021, pp. 284– 288, Mar. 2021, doi: 10.1109/ICAIS50930.2021.9395797.
[5] S. Neelakandan et al., “Deep Learning Approaches for Cyberbullying Detection and Classification on Social Media,” Comput. Intell. Neurosci., vol. 2022, 2022, doi: 10.1155/2022/2163458.
[6] D. Harish, M. Manimaran, V. P. Jayashakthi, and M. Alamelu, “Automatic Detection of Cyberbullying on Social Media Using Machine Learning,” 2nd Int. Conf. Adv. Electr. Electron. Commun. Comput. Autom. ICAECA 2023, 2023, doi: 10.1109/ICAECA56562.2023.10201149.
[7] B. A. H. Murshed, J. Abawajy, S. Mallappa, M. A. N. Saif, and H. D. E. Al-Ariki, “DEA- RNN: A Hybrid Deep Learning Approach for Cyberbullying Detection in Twitter Social Media Platform,” IEEE Access, vol. 10, pp. 25857–25871, 2022, doi: 10.1109/ACCESS.2022.3153675.
[8] S. B. Shanto, M. J. Islam, and M. A. Samad, “Cyberbullying Detection using Deep Learning Techniques on Bangla Facebook Comments,” Proc. 2023 Int. Conf. Intell. Syst. Adv. Comput. Commun. ISACC 2023, 2023, doi: 10.1109/ISACC56298.2023.10083690.
[9] V. Jain, A. K. Saxena, A. Senthil, A. Jain, and A. Jain, “Cyber-Bullying Detection in Social Media Platform using Machine Learning,” Proc. 2021 10th Int. Conf. Syst. Model. Adv. Res. Trends, SMART 2021, pp. 401–405, 2021, doi: 10.1109/SMART52563.2021.9676194.
[10] N. Islam, R. Haque, P. K. Pareek, M. B. Islam, I. H. Sajeeb, and M. H. Ratul, “Deep
Learning for Multi-Labeled Cyberbully Detection: Enhancing Online Safety,” 2023 Int. Conf. Data
Sci. Netw. Secur. ICDSNS 2023, 2023, doi: 10.1109/ICDSNS58469.2023.10245135.
[11] M. M. Islam, M. A. Uddin, L. Islam, A. Akter, S. Sharmin, and U. K. Acharjee, “Cyberbullying Detection on Social Networks Using Machine Learning Approaches,” 2020 IEEE Asia-Pacific Conf. Comput. Sci. Data Eng. CSDE 2020, Dec. 2020, doi: 10.1109/CSDE50874.2020.9411601.
[12] M. S. Nikhila, A. Bhalla, and P. Singh, “Text Imbalance Handling and Classification for Cross- platform Cyber-crime Detection using Deep Learning,” 2020 11th Int. Conf. Comput. Commun. Netw. Technol. ICCCNT 2020, Jul. 2020, doi: 10.1109/ICCCNT49239.2020.9225402.
[13] S. Pericherla and E. Ilavarasan, “Performance analysis of Word Embeddings for Cyberbullying Detection,” IOP Conf. Ser. Mater. Sci. Eng., vol. 1085, no. 1, p. 012008, Feb. 2021, doi: 10.1088/1757-899X/1085/1/012008.
[14] E. Idrizi and M. Hamiti, “Classification of Text, Image and Audio Messages Used for Cyberbulling on Social Medias,” 2023 46th ICT Electron. Conv. MIPRO 2023 - Proc., pp. 797– 802, 2023, doi: 10.23919/MIPRO57284.2023.10159835.
[15] M. Alotaibi, B. Alotaibi, and A. Razaque, “A Multichannel Deep Learning Framework for Cyberbullying Detection on Social Media,” Electron. 2021, Vol. 10, Page 2664, vol. 10, no. 21, p. 2664, Oct. 2021, doi: 10.3390/ELECTRONICS10212664.
[16] R. Beniwal, S. Jha, S. Mehta, and R. Dhiman, “Cyberbullying Detection using Deep Learning Models in Bengali Language,” 2023 3rd Int. Conf. Intell. Technol. CONIT 2023, 2023, doi: 10.1109/CONIT59222.2023.10205775.
[17] C. S. Wu and U. Bhandary, “Detection of Hate Speech in Videos Using Machine Learning,” Proc. - 2020 Int. Conf. Comput. Sci. Comput. Intell. CSCI 2020, pp. 585–590, Dec. 2020, doi: 10.1109/CSCI51800.2020.00104.
[18] S. M. Kargutkar and V. Chitre, “A Study of Cyberbullying Detection Using Machine Learning Techniques,” Proc. 4th Int. Conf. Comput. Methodol. Commun. ICCMC 2020, pp. 734– 739, Mar. 2020, doi: 10.1109/ICCMC48092.2020.ICCMC-000137.
[19] M. Behzadi, I. G. Harris, and A. Derakhshan, “Rapid Cyber-bullying detection method using Compact BERT Models,” Proc. - 2021 IEEE 15th Int. Conf. Semant. Comput. ICSC 2021, pp. 199–202, Jan. 2021, doi: 10.1109/ICSC50631.2021.00042.
[20] R. R. Dalvi, S. Baliram Chavan, and A. Halbe, “Detecting A Twitter Cyberbullying Using Machine Learning,” Proc. Int. Conf. Intell. Comput. Control Syst. ICICCS 2020, pp. 297–301, May 2020, doi: 10.1109/ICICCS48265.2020.9120893.
[21] R. Shah and S. K. J. Somaiya, “Machine Learning based Approach for Detection of Cyberbullying Tweets,” Int. J. Comput. Appl., vol. 175, no. 37, pp. 975–8887, 2020.
[22] A. Muneer and S. M. Fati, “A Comparative Analysis of Machine Learning Techniques for Cyberbullying Detection on Twitter,” Futur. Internet 2020, Vol. 12, Page 187, vol. 12, no. 11, p. 187, Oct. 2020, doi: 10.3390/FI12110187.
[23] R. Kumar and A. Bhat, “A study of machine learning-based models for detection, control, and mitigation of cyberbullying in online social media,” Int. J. Inf. Secur., vol. 21, no. 6, pp. 1409– 1431, Dec. 2022, doi: 10.1007/S10207-022-00600-Y/METRICS.
[24] K. Wang, Q. Xiong, C. Wu, M. Gao, and Y. Yu, “Multi-modal cyberbullying detection on social networks,” Proc. Int. Jt. Conf. Neural Networks, Jul. 2020, doi: 10.1109/IJCNN48605.2020.9206663.