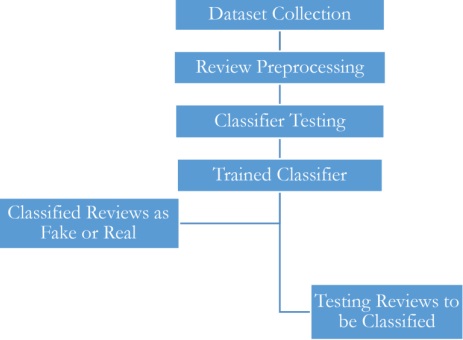
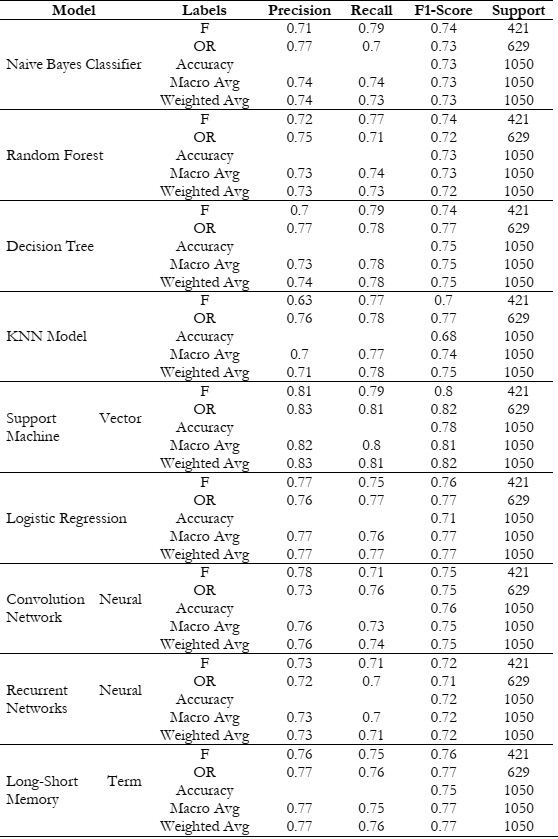
Going forward in the results section, we present our thorough experiment results after running nine machine learning models on the dataset and analyzing the model performance by using the given metrics; recall, precision, and f1-score. For training purposes, 30% of the data has been utilized while 70% has been allocated for testing. The performance of all models is shown in Figure 2.
Neural networks are widely regarded as the most efficient and powerful models in the field of machine learning. On our dataset, neural networks did not outperform traditional machine learning algorithms as their performance directly relates to the quantity of the dataset. Producing an f1-score of 0.82, the SVM demonstrated superior performance compared to the other models. Figure 2 shows a comparison of the f1-scores of all the models. In our research, we have chosen the most processed dataset by performing TF-IDF on BoW to obtain well-related instances to minimize overfitting. By tuning preprocessing and applying TF-IDF on BoW, we were able to improve the accuracy and found the Support Vector Machine as the most outperforming model compared to the rest.
[1] R. Xu, Y. Xia, K.-F. Wong, and W. Li, “Opinion Annotation in On-line Chinese Product Reviews.” 2008. Accessed: Dec. 25, 2023. [Online]. Available: http://www.lrec-conf.org/proceedings/lrec2008/pdf/415_paper.pdf
[2] A. K. Samha, Y. Li, and J. Zhang, “Aspect-Based Opinion Extraction from Customer Reviews,” pp. 149–160, Apr. 2014, doi: 10.5121/csit.2014.4413.
[3] I. Peñalver-Martinez et al., “Feature-based opinion mining through ontologies,” Expert Syst. Appl., vol. 41, no. 13, pp. 5995–6008, Oct. 2014, doi: 10.1016/J.ESWA.2014.03.022.
[4] A. M. Popescu and O. Etzioni, “Extracting product features and opinions from reviews,” Nat. Lang. Process. Text Min., pp. 9–28, 2007, doi: 10.1007/978-1-84628-754-1_2/COVER.
[5] M. Hu and B. Liu, “Mining and summarizing customer reviews,” KDD-2004 - Proc. Tenth ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., pp. 168–177, 2004, doi: 10.1145/1014052.1014073.
[6] N. N. Ho-Dac, S. J. Carson, and W. L. Moore, “The Effects of Positive and Negative Online Customer Reviews: Do Brand Strength and Category Maturity Matter?,” https://doi.org/10.1509/jm.11.0011, vol. 77, no. 6, pp. 37–53, Nov. 2013, doi: 10.1509/JM.11.0011.
[7] F. Zhu and X. (Michael) Zhang, “Impact of Online Consumer Reviews on Sales: The Moderating Role of Product and Consumer Characteristics,” https://doi.org/10.1509/jm.74.2.133, vol. 74, no. 2, pp. 133–148, Mar. 2010, doi: 10.1509/JM.74.2.133.
[8] J. Ye and L. Akoglu, “Discovering opinion spammer groups by network footprints,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 9284, pp. 267–282, 2015, doi: 10.1007/978-3-319-23528-8_17/COVER.
[9] C. Jiang, X. Zhang, and A. Jin, “Detecting Online Fake Reviews via Hierarchical Neural Networks and Multivariate Features,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 12532 LNCS, pp. 730–742, 2020, doi: 10.1007/978-3-030-63830-6_61/COVER.
[10] Y. Li, F. Wang, S. Zhang, and X. Niu, “Detection of Fake Reviews Using Group Model,” Mob. Networks Appl., vol. 26, no. 1, pp. 91–103, Feb. 2021, doi: 10.1007/S11036-020-01688-Z/METRICS.
[11] R. Mohawesh, S. Tran, R. Ollington, and S. Xu, “Analysis of concept drift in fake reviews detection,” Expert Syst. Appl., vol. 169, p. 114318, May 2021, doi: 10.1016/J.ESWA.2020.114318.
[12] G. Satia Budhi, R. Chiong, Z. Wang, and S. Dhakal, “Using a hybrid content-based and behavior-based featuring approach in a parallel environment to detect fake reviews,” Electron. Commer. Res. Appl., vol. 47, p. 101048, May 2021, doi: 10.1016/J.ELERAP.2021.101048.
[13] F. Abri, L. F. Gutierrez, A. S. Namin, K. S. Jones, and D. R. W. Sears, “Linguistic Features for Detecting Fake Reviews,” Proc. - 19th IEEE Int. Conf. Mach. Learn. Appl. ICMLA 2020, pp. 352–359, Dec. 2020, doi: 10.1109/ICMLA51294.2020.00063.
[14] H. Li, Z. Chen, B. Liu, X. Wei, and J. Shao, “Spotting Fake Reviews via Collective Positive-Unlabeled Learning,” Proc. - IEEE Int. Conf. Data Mining, ICDM, vol. 2015-January, no. January, pp. 899–904, Jan. 2014, doi: 10.1109/ICDM.2014.47.
[15] A. Heydari, M. A. Tavakoli, N. Salim, and Z. Heydari, “Detection of review spam: A survey,” Expert Syst. Appl., vol. 42, no. 7, pp. 3634–3642, May 2015, doi: 10.1016/J.ESWA.2014.12.029.
[16] M. Ott, Y. Choi, C. Cardie, and J. T. Hancock, “Finding Deceptive Opinion Spam by Any Stretch of the Imagination,” ACL-HLT 2011 - Proc. 49th Annu. Meet. Assoc. Comput. Linguist. Hum. Lang. Technol., vol. 1, pp. 309–319, Jul. 2011, Accessed: Dec. 25, 2023. [Online]. Available: https://arxiv.org/abs/1107.4557v1
[17] S. Feng, R. Banerjee, and Y. Choi, “Syntactic Stylometry for Deception Detection.” Association for Computational Linguistics, pp. 171–175, 2012. Accessed: Dec. 25, 2023. [Online]. Available: https://aclanthology.org/P12-2034
[18] E. Elmurngi and A. Gherbi, “An empirical study on detecting fake reviews using machine learning techniques,” 7th Int. Conf. Innov. Comput. Technol. INTECH 2017, pp. 107–114, Nov. 2017, doi: 10.1109/INTECH.2017.8102442.
[19] V. K. Singh, R. Piryani, A. Uddin, and P. Waila, “Sentiment analysis of Movie reviews and Blog posts,” Proc. 2013 3rd IEEE Int. Adv. Comput. Conf. IACC 2013, pp. 893–898, 2013, doi: 10.1109/IADCC.2013.6514345.
[20] A. Molla, Y. Biadgie, and K. A. Sohn, “Detecting negative deceptive opinion from tweets,” Lect. Notes Electr. Eng., vol. 425, pp. 329–339, 2018, doi: 10.1007/978-981-10-5281-1_36/COVER.
[21] S. Shojaee, M. A. A. Murad, A. Bin Azman, N. M. Sharef, and S. Nadali, “Detecting deceptive reviews using lexical and syntactic features,” Int. Conf. Intell. Syst. Des. Appl. ISDA, pp. 53–58, Oct. 2014, doi: 10.1109/ISDA.2013.6920707.
[22] G. G. Chowdhury, “Natural language processing,” Annu. Rev. Inf. Sci. Technol., vol. 37, no. 1, pp. 51–89, 2003.
[23] C. Silva and B. Ribeiro, “The Importance of Stop Word Removal on Recall Values in Text Categorization,” Proc. Int. Jt. Conf. Neural Networks, vol. 3, pp. 1661–1666, 2003, doi: 10.1109/IJCNN.2003.1223656.
[24] J. Plisson, N. Lavrač, and D. Mladenić, “A Rule-based Approach to Word Lemmatization,” 2004.
[25] C. Lee and D. A. Landgrebe, “Feature Extraction Based on Decision Boundaries,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 15, no. 4, pp. 388–400, 1993, doi: 10.1109/34.206958.
[26] N. Jindal and B. Liu, “Review spam detection,” 16th Int. World Wide Web Conf. WWW2007, pp. 1189–1190, 2007, doi: 10.1145/1242572.1242759.
[27] R. Mihalcea, C. Corley, and C. Strapparava, “Corpus-based and Knowledge-based Measures of Text Semantic Similarity”, Accessed: Dec. 25, 2023. [Online]. Available: www.aaai.org
[28] J. Ramos, “Using TF-IDF to Determine Word Relevance in Document Queries,” Proc. first Instr. Conf. Mach. Learn., vol. 242, no. 1, pp. 29–48.