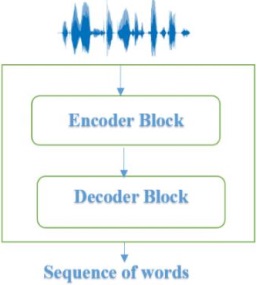
The performance of an ASR system is typically evaluated using the word error rate (WER) and character error rate (CER) metrics [38]. This metric calculates the percentage of errors made by the ASR system relative to the reference transcript. It is calculated in Eq 3. And Eq 4. A lower WER score is desired.
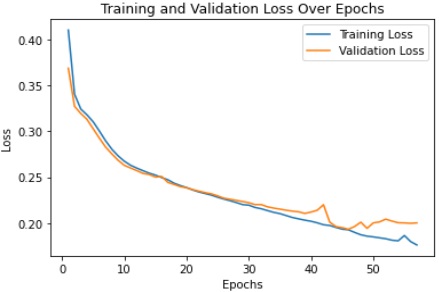
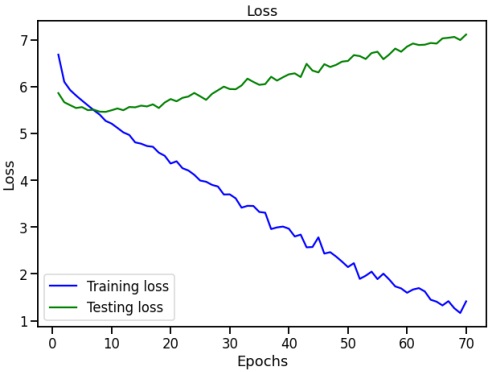
During experimentations, we have analyzed the influence of dataset size in different manners. Like, its effect on the training and validation loss curves of the proposed model. We have conducted experiments on both small and large datasets to comprehensively analyze the implications. One notable observation of experiments is the relationship between dataset size and the risk of overfitting. With smaller datasets, the model exhibited signs of overfitting, achieving lower training loss but struggling to generalize to unseen data. The scarcity of examples in smaller datasets led to over-optimization, emphasizing the importance of having an adequate amount of diverse data for robust model training. Smaller datasets demonstrated higher fluctuations in both training and validation loss curves. These fluctuations suggest that the model's performance is highly sensitive to the limited data available. In contrast, larger datasets contributed to more stable loss curves, indicating improved reliability in assessing the model's generalization capabilities. Figure 4 and Figure 5 show training vs validation loss curves for less data as well as adequate data. Loss curves provide valuable insights into the evolution of learning performance across epochs, aiding in the identification of potential issues that may result in either underfitting or overfitting of the model. Our experiments revealed intriguing insights into the convergence speed concerning dataset size. Models trained on smaller datasets tended to converge faster, possibly due to the reduced complexity of the training task. However, this expedited convergence came at the expense of compromised generalization. It took 7 hours on GPU to run for 100 epochs when training was done using 10 hours of data. While for 100-hour data it took 33 hours on GPU.
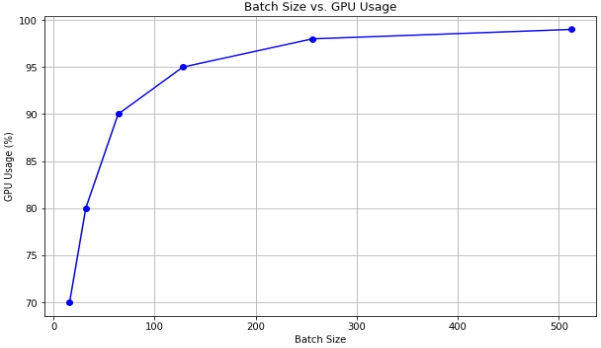
The batch size, representing the number of training samples processed in each iteration, was set to balance computational efficiency and memory constraints. A moderate batch size was chosen to allow for parallelization without compromising model stability. As we increase the batch size, the GPU is utilized more effectively. Larger batches often result in higher GPU usage during training. This is because more data is processed in parallel, exploiting the parallel processing capabilities of modern GPUs. However, increasing the batch size comes with memory requirements. Larger batches consume more GPU memory. When the batch size was too large for the GPU memory, it led to out-of-memory errors, preventing the model from training. However small batch sizes resulted in underutilization of the GPU, as it may not be fully occupied with computations. This led to lower efficiency and reduced throughput. On the other hand, extremely large batches lead to diminishing returns in terms of GPU utilization. There is an optimal batch size that balances GPU usage and computational efficiency. The figure 6 shows batch size vs GPU utilization.
Code is written in Python using KERAS which is a deep-learning API. Experiments were run on the server with NVIDIA RTX A6000. It took 7 hours on GPU to run for 100 epochs. In the experiments, corpora with varying amounts of data were utilized. The reduction in data quantity resulted in a decline in speech recognition accuracy. The model was overfitting by increasing the drop rate the problem was resolved. A series of experiments with varying dropout rates to understand its influence on the recognition task was conducted. Dropout rates of 0.2, 0.5, and 0.8 were selected to represent low, moderate, and high dropout scenarios. Surprisingly, the recognition accuracy significantly degraded when a high dropout rate of 0.8 was employed. This result contrasts with the common expectation that dropout generally improves generalization. Different learning rates were experimented best results were acquired with a learning rate of 0.00001. Similarly, nominal results were gained after training to 100 epochs. Models based on E2E models have a reliable recognition tendency but suffer from a delay due to the need to wait for each audio utterance to process data. This delay restricts their use in real-time speech recognition, making it essential to consider methods that can handle streaming speech to address this limitation. An example of text sequence predicted by the model compared with the ground-truth at or around 100 epochs is depicted in Table 4, Table 5, and Table 6: when tested on unseen data WER achieved 76% with 10 hours of training data. When trained on 200 hours of data WER improved to 51 % and CER 29%. When tested on training data CER 14.42% and WER 9.41% were achieved.
In the experiments, corpora with varying amounts of data were utilized. The reduction in data quantity resulted in a decline in speech recognition accuracy. The model was overfitting by increasing the drop rate the problem was resolved. Different learning rates were experimented best results were acquired with a learning rate of 0.00001. Similarly, nominal results were gained after training to 100 epochs. Models based on E2E models have a reliable recognition tendency but suffer from a delay due to the need to wait for each audio utterance to process data. This delay restricts their use in real-time speech recognition, making it essential to consider methods that can handle streaming speech to address this limitation. Smaller datasets demonstrated higher fluctuations in both training and validation loss curves. These fluctuations suggested that the model's performance is highly sensitive to the limited data available. Our experiments revealed intriguing insights into the convergence speed concerning dataset size. Models trained on smaller datasets tended to converge faster, possibly due to the reduced complexity of the training task. However, this expedited convergence came at the expense of compromised generalization. It took 7 hours on GPU to run for 100 epochs when training was done using 10 hours of data. While for 200-hour data it took 33 hours on GPU. Our experimentation also showed larger batches consume more GPU memory. when the batch size was too large for the GPU memory, it led to out-of-memory errors, preventing the model from training. However small batch sizes resulted in underutilization of the GPU, as it may not be fully occupied with computations. This leads to lower efficiency and reduced throughput. On the other hand, extremely large batches lead to diminishing returns in terms of GPU utilization. There is an optimal batch size that balances GPU usage and computational efficiency. Experimental results for small sentences, defined as sentences with less than 8 words, the model consistently exhibited improved performance as the number of training epochs increased. Conversely, for larger sentences (defined as sentences with more than 20 words) results were degraded. Similarly, experimentations showed that increasing the number of decoders also resulted in degradation of results and out-of-memory issues as well.
The outcomes of the experiments investigating the influence of varying the number of decoders in the model are also tested. The objective of these experiments was to assess the performance improvements that could be achieved through the augmentation of model complexity. However, contrary to the initial hypothesis, the results revealed a discernible deterioration in overall performance as the number of decoders increased. The experimental setup involved systematically increasing the number of decoders in the Transformer architecture while keeping other hyperparameters constant. Performance metrics, including Word Error Rate (WER), were employed to evaluate the impact on the speech recognition system. Graphs in Figure 7 show overfitting occurred when a greater number of decoders were used and the best results were achieved with a single decoder. The increased model complexity may have introduced challenges in training, potentially resulting in overfitting or difficulties in capturing relevant acoustic features. This unexpected trend challenges the conventional assumption that a more complex model with additional decoders would inherently yield better results. It is plausible that the deeper architecture introduced challenges in training, leading to difficulties in capturing relevant speech features.
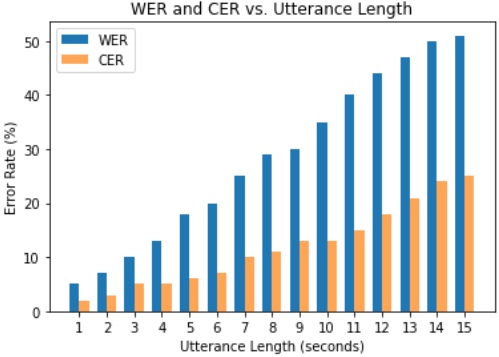
Experimental results for small sentences, defined as sentences with less than 8 words, the model consistently exhibited improved performance as the number of training epochs increased. Conversely, for larger sentences (defined as sentences with more than 20 words), the gains observed with additional epochs were marginal. This suggests that the model is able to accurately transcribe short and concise utterances. Our analysis revealed the superior performance of the model when handling short utterances. Figure 8 illustrates the recognition accuracy for different utterance lengths, showcasing a distinct advantage for utterances with fewer temporal dependencies. On the other hand, the model encountered challenges when confronted with longer utterances. While the recognition accuracy remained competitive for short and medium-length utterances, a noticeable decline was observed as the temporal span of the utterances increased. The observed performance trends suggest a potential sensitivity of the model to the temporal context inherent in longer utterances.
[1] A. P. Singh, R. Nath, and S. Kumar, “A Survey: Speech Recognition Approaches and Techniques,” 2018 5th IEEE Uttar Pradesh Sect. Int. Conf. Electr. Electron. Comput. Eng. UPCON 2018, Dec. 2018, doi: 10.1109/UPCON.2018.8596954.
[2] C. Kim et al., “End-To-End Training of a Large Vocabulary End-To-End Speech Recognition System,” 2019 IEEE Autom. Speech Recognit. Underst. Work. ASRU 2019 - Proc., pp. 562–569, Dec. 2019, doi: 10.1109/ASRU46091.2019.9003976.
[3] D. Wang, X. Wang, and S. Lv, “An Overview of End-to-End Automatic Speech Recognition,” Symmetry 2019, Vol. 11, Page 1018, vol. 11, no. 8, p. 1018, Aug. 2019, doi: 10.3390/SYM11081018.
[4] S. Khare, A. Mittal, A. Diwan, S. Sarawagi, P. Jyothi, and S. Bharadwaj, “Low Resource ASR: The Surprising Effectiveness of High Resource Transliteration,” Proc. Annu. Conf. Int. Speech Commun. Assoc. INTERSPEECH, vol. 2, pp. 1529–1533, 2021, doi: 10.21437/INTERSPEECH.2021-2062.
[5] S. P. Rath, K. M. Knill, A. Ragni, and M. J. F. Gales, “Combining tandem and hybrid systems for improved speech recognition and keyword spotting on low resource languages,” Proc. Annu. Conf. Int. Speech Commun. Assoc. INTERSPEECH, pp. 835–839, 2014, doi: 10.21437/INTERSPEECH.2014-212.
[6] O. Scharenborg et al., “Building an ASR System for a Low-research Language Through the Adaptation of a High-resource Language ASR System: Preliminary Results”.
[7] Z. Tüske, P. Golik, D. Nolden, R. Schlüter, and H. Ney, “Data augmentation, feature combination, and multilingual neural networks to improve ASR and KWS performance for low-resource languages,” Proc. Annu. Conf. Int. Speech Commun. Assoc. INTERSPEECH, pp. 1420–1424, 2014, doi: 10.21437/INTERSPEECH.2014-348.
[8] M. Y. Tachbelie and L. Besacier, “Using different acoustic, lexical and language modeling units for ASR of an under-resourced language – Amharic,” Speech Commun., vol. 56, no. 1, pp. 181–194, Jan. 2014, doi: 10.1016/J.SPECOM.2013.01.008.
[9] D. Rudolph Van Niekerk, “AUTOMATIC SPEECH SEGMENTATION WITH LIMITED DATA”.
[10] P. Swietojanski, A. Ghoshal, and S. Renals, “Revisiting hybrid and GMM-HMM system combination techniques,” ICASSP, IEEE Int. Conf. Acoust. Speech Signal Process. - Proc., pp. 6744–6748, Oct. 2013, doi: 10.1109/ICASSP.2013.6638967.
[11] P. Motlicek, D. Imseng, B. Potard, P. N. Garner, and I. Himawan, “Exploiting foreign resources for DNN-based ASR,” Eurasip J. Audio, Speech, Music Process., vol. 2015, no. 1, pp. 1–10, Dec. 2015, doi: 10.1186/S13636-015-0058-5/TABLES/5.
[12] S. Kim, T. Hori, and S. Watanabe, “Joint CTC-attention based end-to-end speech recognition using multi-task learning,” ICASSP, IEEE Int. Conf. Acoust. Speech Signal Process. - Proc., pp. 4835–4839, Jun. 2017, doi: 10.1109/ICASSP.2017.7953075.
[13] S. Ding, S. Qu, Y. Xi, A. K. Sangaiah, and S. Wan, “Image caption generation with high-level image features,” Pattern Recognit. Lett., vol. 123, pp. 89–95, May 2019, doi: 10.1016/J.PATREC.2019.03.021.
[14] H. Tsaniya, C. Fatichah, and N. Suciati, “Transformer Approaches in Image Captioning: A Literature Review,” ICITEE 2022 - Proc. 14th Int. Conf. Inf. Technol. Electr. Eng., pp. 280–285, 2022, doi: 10.1109/ICITEE56407.2022.9954086.
[15] G. Liu and J. Guo, “Bidirectional LSTM with attention mechanism and convolutional layer for text classification,” Neurocomputing, vol. 337, pp. 325–338, Apr. 2019, doi: 10.1016/J.NEUCOM.2019.01.078.
[16] Y. Li, L. Yang, B. Xu, J. Wang, and H. Lin, “Improving User Attribute Classification with Text and Social Network Attention,” Cognit. Comput., vol. 11, no. 4, pp. 459–468, Aug. 2019, doi: 10.1007/S12559-019-9624-Y/METRICS.
[17] M. A. Di Gangi, M. Negri, and M. Turchi, “Adapting Transformer to End-to-End Spoken Language Translation,” Proc. Annu. Conf. Int. Speech Commun. Assoc. INTERSPEECH, vol. 2019-September, pp. 1133–1137, 2019, doi: 10.21437/INTERSPEECH.2019-3045.
[18] D. Britz, A. Goldie, M. T. Luong, and Q. V. Le, “Massive Exploration of Neural Machine Translation Architectures,” EMNLP 2017 - Conf. Empir. Methods Nat. Lang. Process. Proc., pp. 1442–1451, 2017, doi: 10.18653/V1/D17-1151.
[19] A. Rahali and M. A. Akhloufi, “End-to-End Transformer-Based Models in Textual-Based NLP,” AI 2023, Vol. 4, Pages 54-110, vol. 4, no. 1, pp. 54–110, Jan. 2023, doi: 10.3390/AI4010004.
[20] Y. Zhang, P. Wu, H. Li, Y. Liu, F. E. Alsaadi, and N. Zeng, “DPF-S2S: A novel dual-pathway-fusion-based sequence-to-sequence text recognition model,” Neurocomputing, vol. 523, pp. 182–190, Feb. 2023, doi: 10.1016/J.NEUCOM.2022.12.034.
[21] S. Song, C. Lan, J. Xing, W. Zeng, and J. Liu, “An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data,” Proc. AAAI Conf. Artif. Intell., vol. 31, no. 1, pp. 4263–4270, Feb. 2017, doi: 10.1609/AAAI.V31I1.11212.
[22] X. Yan, S. Hu, Y. Mao, Y. Ye, and H. Yu, “Deep multi-view learning methods: A review,” Neurocomputing, vol. 448, pp. 106–129, Aug. 2021, doi: 10.1016/J.NEUCOM.2021.03.090.
[23] K. Song, T. Yao, Q. Ling, and T. Mei, “Boosting image sentiment analysis with visual attention,” Neurocomputing, vol. 312, pp. 218–228, Oct. 2018, doi: 10.1016/J.NEUCOM.2018.05.104.
[24] S. Ahmadian, M. Ahmadian, and M. Jalili, “A deep learning based trust- and tag-aware recommender system,” Neurocomputing, vol. 488, pp. 557–571, Jun. 2022, doi: 10.1016/J.NEUCOM.2021.11.064.
[25] R. Wang, Z. Wu, J. Lou, and Y. Jiang, “Attention-based dynamic user modeling and Deep Collaborative filtering recommendation,” Expert Syst. Appl., vol. 188, p. 116036, Feb. 2022, doi: 10.1016/J.ESWA.2021.116036.
[26] J. Feng et al., “Crowd Flow Prediction for Irregular Regions with Semantic Graph Attention Network,” ACM Trans. Intell. Syst. Technol., vol. 13, no. 5, Jun. 2022, doi: 10.1145/3501805.
[27] S. Liang, A. Zhu, J. Zhang, and J. Shao, “Hyper-node Relational Graph Attention Network for Multi-modal Knowledge Graph Completion,” ACM Trans. Multimed. Comput. Commun. Appl., vol. 19, no. 2, Feb. 2023, doi: 10.1145/3545573.
[28] X. Yan, Y. Guo, G. Wang, Y. Kuang, Y. Li, and Z. Zheng, “Fake News Detection Based on Dual Graph Attention Networks,” Lect. Notes Data Eng. Commun. Technol., vol. 89, pp. 655–666, 2022, doi: 10.1007/978-3-030-89698-0_67/COVER.
[29] L. Besacier, E. Barnard, A. Karpov, and T. Schultz, “Automatic speech recognition for under-resourced languages: A survey,” Speech Commun., vol. 56, no. 1, pp. 85–100, Jan. 2014, doi: 10.1016/J.SPECOM.2013.07.008.
[30] I. Ahmed, H. Ali, N. Ahmad, and G. Ahmad, “The development of isolated words corpus of Pashto for the automatic speech recognition research,” 2012 Int. Conf. Robot. Artif. Intell. ICRAI 2012, pp. 139–143, 2012, doi: 10.1109/ICRAI.2012.6413380.
[31] Z. Ali, A. W. Abbas, T. M. Thasleema, B. Uddin, T. Raaz, and S. A. R. Abid, “Database development and automatic speech recognition of isolated Pashto spoken digits using MFCC and K-NN,” Int. J. Speech Technol., vol. 18, no. 2, pp. 271–275, Jun. 2015, doi: 10.1007/S10772-014-9267-Z/METRICS.
[32] B. Zada and R. Ullah, “Pashto isolated digits recognition using deep convolutional neural network,” Heliyon, vol. 6, no. 2, p. e03372, Feb. 2020, doi: 10.1016/j.heliyon.2020.e03372.
[33] Z. Alyafeai, M. S. AlShaibani, and I. Ahmad, “A Survey on Transfer Learning in Natural Language Processing,” arXiv, pp. 6523–6541, May 2020, Accessed: Feb. 16, 2024. [Online]. Available: https://arxiv.org/abs/2007.04239v1
[34] Y. Li, S. Si, G. Li, C. J. Hsieh, and S. Bengio, “Learnable Fourier Features for Multi-Dimensional Spatial Positional Encoding,” Adv. Neural Inf. Process. Syst., vol. 19, pp. 15816–15829, Jun. 2021, Accessed: Feb. 16, 2024. [Online]. Available: https://arxiv.org/abs/2106.02795v3
[35] M. Cai et al., “High-performance Swahili keyword search with very limited language pack: The THUEE system for the OpenKWS15 evaluation,” 2015 IEEE Work. Autom. Speech Recognit. Understanding, ASRU 2015 - Proc., pp. 215–222, Feb. 2016, doi: 10.1109/ASRU.2015.7404797.
[36] P. E. Solberg, P. Beauguitte, P. E. Kummervold, and F. Wetjen, “A Large Norwegian Dataset for Weak Supervision ASR.” pp. 48–52, 2023. Accessed: Feb. 16, 2024. [Online]. Available: https://aclanthology.org/2023.resourceful-1.7
[37] P. Janbakhshi and I. Kodrasi, “EXPERIMENTAL INVESTIGATION ON STFT PHASE REPRESENTATIONS FOR DEEP LEARNING-BASED DYSARTHRIC SPEECH DETECTION,” ICASSP, IEEE Int. Conf. Acoust. Speech Signal Process. - Proc., vol. 2022-May, pp. 6477–6481, 2022, doi: 10.1109/ICASSP43922.2022.9747205.
[38] W. Chan, N. Jaitly, Q. V Le, and V. Google Brain, “Listen, Attend and Spell,” Aug. 2015, Accessed: Feb. 16, 2024. [Online]. Available: https://arxiv.org/abs/1508.01211v2