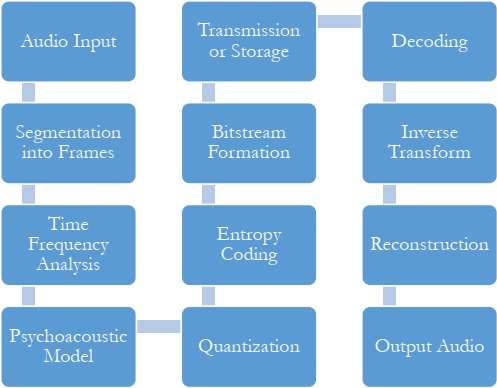
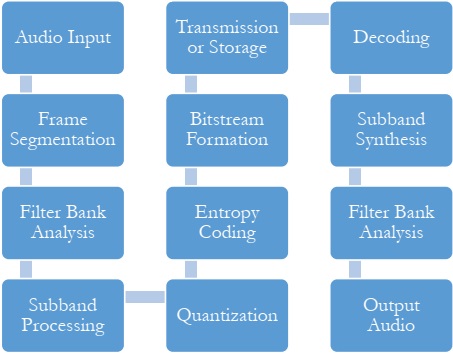
The performance evaluation of the audio compression algorithms revealed distinct outcomes across various metrics. Metrics such as Mean Square Error (MSE) and Total Harmonic Distortion (THD) gauge the fidelity of compressed audio compared to the original, with lower values indicating superior preservation of audio quality. Perceptual Evaluation of Speech Quality (PESQ) assesses the perceived quality of the compressed audio, with higher scores signifying better perceived quality. The structural Similarity Index (SSI) measures the similarity between the original and compressed audio signals, where higher values denote better preservation of structural information. The measurement and comparison of metrics across different audio compression algorithms involved a systematic process of quantitative analysis, statistical evaluation, and visualization.
MSE is computed by taking the average squared difference between corresponding samples of the uncompressed and compressed audio waveforms. This metric quantifies the disparity between the original and compressed signals, with lower MSE values indicating a stronger similarity between the two signals and thus superior preservation of the audio quality. THD quantifies the level of harmonic distortion introduced during the compression process, particularly in audio signals with harmonic content such as music. It calculates the ratio between the total power of all harmonic components and the power of the fundamental frequency. Lower THD values suggest reduced harmonic distortion and better preservation of the original audio's harmonic content. PESQ is a standardized algorithm designed to assess the perceived quality of speech signals after compression. It operates by comparing the original speech signal with the compressed version and assigning a quality score based on perceived speech intelligibility and fidelity. Higher PESQ scores indicate enhanced perceptual quality, signaling the effectiveness of the compression algorithm in maintaining speech clarity and naturalness. SSI measures the similarity between the original and compressed audio signals in terms of both luminance and contrast. It evaluates structural distortions introduced by the compression process, accounting for perceptual differences in texture, luminance, and spatial layout. Higher SSI values signify a greater degree of similarity between the original and compressed signals, indicating minimal distortion and preserving structural integrity.
Each metric (MSE, THD, PESQ, SSI) was computed for the output of each compression algorithm applied to the audio files. This yielded a set of numerical values representing the performance of each algorithm across different evaluation criteria. The numerical values obtained for each metric were statistically analyzed to identify trends and patterns in algorithm performance. This involved calculating summary statistics such as mean, median, and standard deviation, as well as conducting hypothesis tests to assess the significance of differences between algorithms. The results of the quantitative and statistical analyses were visually represented using graphs and tables. This allowed for a clear and intuitive comparison of algorithm performance across different metrics, facilitating the identification of strengths and weaknesses in each algorithm. These metrics collectively offered insights into the efficacy of each compression algorithm across different dimensions of audio quality and compression efficiency.
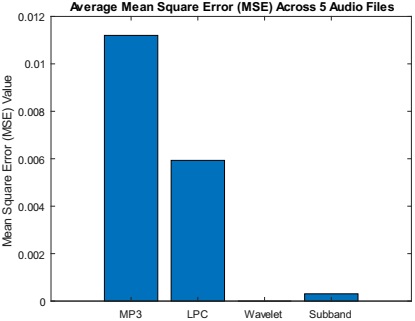
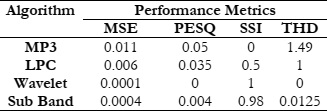
The Mean Squared Error (MSE) comparison graph in Figure 7 provides insights into various audio compression algorithms, with MSE values depicted on the y-axis and specific algorithms on the x-axis. Among the algorithms analyzed, the MP3 audio compression algorithm exhibited the highest MSE of 0.011, suggesting more distortion compared to the original audio signal. In contrast, the LPC audio compression algorithm achieved a lower MSE of 0.006, indicating better preservation of audio quality with reduced distortion. Notably, the Wavelet audio compression algorithm demonstrated the lowest MSE of 0.0001, signifying minimal distortion and high fidelity in audio compression. The Subband audio compression algorithm falls between these extremes, with an MSE of 0.0004, offering a balance between compression efficiency and audio quality preservation. In summary, while the MP3 algorithm sacrificed some audio quality for compression, the LPC, Wavelet, and Subband algorithms prioritized fidelity and efficiency, with the Wavelet algorithm distinguished itself for exceptional performance in minimizing distortion and preserving audio quality.
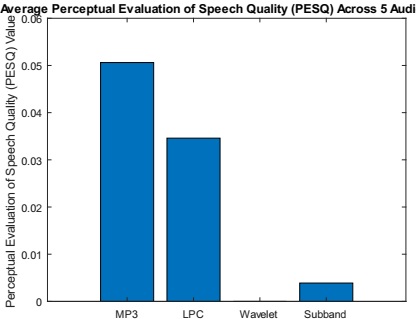
The PESQ comparison graph in Figure 8 provides a comprehensive analysis of various audio compression algorithms, with PESQ scores represented on the y-axis and specific algorithms on the x-axis. Among the algorithms assessed, the MP3 audio compression algorithm recorded a PESQ score of 0.05, indicating a moderate level of speech quality preservation but with noticeable degradation compared to the original audio. In contrast, the LPC audio compression algorithm achieved a slightly lower PESQ score of 0.035, suggesting a marginally inferior preservation of speech quality. Remarkably, the Wavelet audio compression algorithm attained a PESQ score of 0, implying an absence of perceived speech distortion and high fidelity in compression. The Subband audio compression algorithm followed closely behind with a PESQ score of 0.004, indicating minimal degradation in speech quality. While the MP3 and LPC algorithms compromised in speech quality for compression purposes, the Wavelet and Subband algorithms outperformed their ability to maintain high fidelity and minimal distortion.
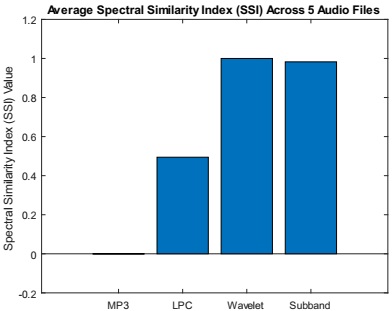
The Structural Similarity Index (SSI) graph in Figure 9 provides a comparative analysis of various audio compression algorithms, with SSI values plotted on the y-axis and specific algorithms listed on the x-axis. The results indicated how closely the compressed audio signals resemble the original signals, with higher SSI values reflecting greater similarity. For instance, the MP3 audio compression algorithm yielded an SSI value of 0, suggesting significant structural differences between the compressed and original signals. In contrast, the LPC audio compression algorithm achieved an SSI value of 0.5, indicating moderate similarity between the compressed and original signals. Remarkably, the Wavelet audio compression algorithm attained an SSI value of 1, signaling near-perfect structural similarity and optimal fidelity in compression. Similarly, the Subband audio compression algorithm demonstrated high performance with an SSI value of 0.98, indicating minimal structural differences and excellent preservation of the original signal's structure.
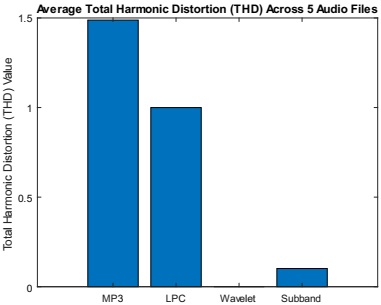
The THD graph in Figure 10 presents a comparative analysis of various audio compression algorithms, with THD values depicted on the y-axis and specific algorithms listed on the x-axis. THD quantified the level of harmonic distortion introduced by compression, where lower values indicated less distortion and higher fidelity. Notably, the MP3 audio compression algorithm exhibited a THD value of 1.49, suggesting noticeable harmonic distortion and potential audio quality degradation. In contrast, the LPC audio compression Algorithm demonstrated a THD value of 1, indicating moderate harmonic distortion but still maintaining acceptable fidelity. Remarkably, both the Wavelet and Subband audio compression algorithms achieved THD values of zero, indicating minimal harmonic distortion and optimal preservation of audio quality.
Table 1 presents a comprehensive overview of MP3, LPC, Wavelet, and Sub band audio compression algorithms. The research paper compares four audio compression algorithms, revealing diverse performance metrics such as MSE, PESQ, SSI, and THD. Practical implications emphasize selecting algorithms based on specific needs; for example, Wavelet excels in minimizing MSE, while Subband balances compression efficiency and fidelity. No single algorithm dominates all aspects, necessitating careful consideration of trade-offs. Ongoing advancements in audio compression promise further refinements, shaping future practical implications.
The findings of this study shed light on the comparative performance of MP3, LPC, Wavelet, and Subband audio compression algorithms across various metrics, providing valuable insights into their effectiveness and practical implications. Comparisons with related research help contextualize these findings within the broader landscape of audio compression technology.
In comparison to prior research by Hidayat, et al. [1], which assessed advanced coding standards for lossless audio compression, our study focuses on lossy compression algorithms and their impact on audio quality. While Hidayat, et al. primarily evaluated compression efficiency and data reduction, our research extends this analysis to encompass perceptual quality and fidelity, providing a more comprehensive understanding of compression algorithm performance. Similarly, the work of Reddy and Vijayarajan [2] on audio compression with multi-algorithm fusion emphasized the importance of integrating multiple compression techniques for enhanced performance. Our study complements this approach by individually evaluating prominent compression algorithms and highlighting their specific strengths and limitations, enabling informed algorithm selection based on application requirements. The research by Abood, et al. [3] on provably secure and efficient audio compression based on compressive sensing offers insights into alternative compression paradigms. While their focus is on security and efficiency, our study emphasizes fidelity and perceptual quality, demonstrating the diverse considerations in audio compression research. Furthermore, Shukla, et al. [5] explored audio compression using discrete cosine transform (DCT) and Lempel-Ziv-Welch (LZW) encoding, emphasizing the importance of transformative techniques in compression. Our study builds upon this foundation by investigating wavelet and subband techniques, showcasing their efficacy in minimizing distortion and preserving audio quality across various scenarios. The comparative analysis presented in our study aligns with the broader trends in audio compression research, emphasizing the trade-offs between compression efficiency, perceptual quality, and fidelity. By providing a nuanced understanding of algorithm performance and practical implications, our findings contribute to the ongoing evolution of audio compression technology, facilitating informed decision-making for diverse applications ranging from telecommunications to multimedia content delivery.
[1] T. Hidayat, M. H. Zakaria, and A. N. C. Pee, “A critical assessment of advanced coding standards for lossless audio compression,” Int. J. Simul. Syst. Sci. Technol., vol. 19, no. 5, pp. 31.1-31.10, Oct. 2018, doi: 10.5013/IJSSST.A.19.05.31.
[2] A. P. Reddy and V. Vijayarajan, “Audio compression with multi-algorithm fusion and its impact in speech emotion recognition,” Int. J. Speech Technol., vol. 23, no. 2, pp. 277–285, Jun. 2020, doi: 10.1007/S10772-020-09689-9/METRICS.
[3] E. W. Abood et al., “Provably secure and efficient audio compression based on compressive sensing,” Int. J. Electr. Comput. Eng., vol. 13, no. 1, pp. 335–346, Feb. 2023, doi: 10.11591/IJECE.V13I1.PP335-346.
[4] M. Bosi and R. E. Goldberg, “Introduction to Digital Audio Coding and Standards,” Introd. to Digit. Audio Coding Stand., 2003, doi: 10.1007/978-1-4615-0327-9.
[5] S. Shukla, M. Ahirwar, R. Gupta, S. Jain, and D. S. Rajput, “Audio Compression Algorithm using Discrete Cosine Transform (DCT) and Lempel-Ziv-Welch (LZW) Encoding Method,” Proc. Int. Conf. Mach. Learn. Big Data, Cloud Parallel Comput. Trends, Prespectives Prospect. Com. 2019, pp. 476–480, Feb. 2019, doi: 10.1109/COMITCON.2019.8862228.
[6] Z. J. Ahmed, L. E. George, and R. A. Hadi, “Audio compression using transforms and high order entropy encoding,” Int. J. Electr. Comput. Eng., vol. 11, no. 4, pp. 3459–3469, Aug. 2021, doi: 10.11591/IJECE.V11I4.PP3459-3469.
[7] A. O. Salau, I. Oluwafemi, K. F. Faleye, and S. Jain, “Audio Compression Using a Modified Discrete Cosine Transform with Temporal Auditory Masking,” 2019 Int. Conf. Signal Process. Commun. ICSC 2019, pp. 135–142, Mar. 2019, doi: 10.1109/ICSC45622.2019.8938213.
[8] A. O. Timothy and G. A. Junior, “Embedding Text in Audio Steganography System using Advanced Encryption Standard, Text Compression and Spread Spectrum Techniques in Mp3 and Mp4 File Formats,” Int. J. Comput. Appl., vol. 177, no. 41, pp. 975–8887, 2020.
[9] S. Prince, D. Bini, A. A. Kirubaraj, S. J. Immanuel, and M. Surya, “Audio Compression using a Modified Vector Quantization algorithm for Mastering Applications,” Int. J. Electron. Telecommun., vol. 69, no. 2, pp. 287–292, 2023, doi: 10.24425/IJET.2023.144363.
[10] J. McFarlane and B. R. Chakravarthi, “MP3 compression classification through audio analysis statistics.” Audio Engineering Society, May 02, 2022. Accessed: Mar. 03, 2024. [Online]. Available: http://www.aes.org/e-lib
[11] B. Gold, N. Morgan, and D. Ellis, “Speech and Audio Signal Processing: Processing and Perception of Speech and Music: Second Edition,” Speech Audio Signal Process. Process. Percept. Speech Music Second Ed., Oct. 2011, doi: 10.1002/9781118142882.
[12] “Discrete-Time Processing of Speech Signals | IEEE eBooks | IEEE Xplore.” Accessed: Mar. 03, 2024. [Online]. Available: https://ieeexplore.ieee.org/book/5266102
[13] X. Liu, H. Tian, Y. Huang, and J. Lu, “A novel steganographic method for algebraic-code-excited-linear-prediction speech streams based on fractional pitch delay search,” Multimed. Tools Appl., vol. 78, no. 7, pp. 8447–8461, Apr. 2019, doi: 10.1007/S11042-018-6867-7/METRICS.
[14] X. Jiang, X. Peng, H. Xue, Y. Zhang, and Y. Lu, “Latent-Domain Predictive Neural Speech Coding,” 2023, doi: 10.1109/TASLP.2023.3277693.
[15] C. Chen, L. Zhang, and R. L. K. Tiong, “A new lossy compression algorithm for wireless sensor networks using Bayesian predictive coding,” Wirel. Networks, vol. 26, no. 8, pp. 5981–5995, Nov. 2020, doi: 10.1007/S11276-020-02425-W/METRICS.
[16] S. Shukla, R. Gupta, D. S. Rajput, Y. Goswami, and V. Sharma, “A Comparative Analysis of Lossless Compression Algorithms on Uniformly Quantized Audio Signals,” Int. J. Image, Graph. Signal Process., vol. 14, no. 6, pp. 59–69, Dec. 2022, doi: 10.5815/IJIGSP.2022.06.05.
[17] et al. Välimäki, Vesa, “Subband synthesis in audio compression,” IEEE Signal Process. Mag., vol. 35, no. 5, pp. 106–126, 2018.
[18] T. P. Zieliński, “Audio Compression,” Textb. Telecommun. Eng., vol. Part F1370, pp. 405–437, 2021, doi: 10.1007/978-3-030-49256-4_15/COVER.
[19] Z.-N. Li, M. S. Drew, and J. Liu, “Basic Audio Compression Techniques,” pp. 479–504, 2021, doi: 10.1007/978-3-030-62124-7_13.
[20] “SIPI Image Database - Misc.” Accessed: Dec. 02, 2023. [Online]. Available: https://sipi.usc.edu/database/database.php?volume=misc
[21] S. T. Abdulrazzaq, M. M. Siddeq, and M. A. Rodrigues, “A Novel Steganography Approach for Audio Files,” SN Comput. Sci., vol. 1, no. 2, pp. 1–13, 2020, doi: 10.1007/s42979-020-0080-2.
[22] N. F. Soliman, M. I. Khalil, A. D. Algarni, S. Ismail, R. Marzouk, and W. El-Shafai, “Efficient HEVC steganography approach based on audio compression and encryption in QFFT domain for secure multimedia communication,” Multimed. Tools Appl., vol. 80, no. 3, pp. 4789–4823, Jan. 2021, doi: 10.1007/S11042-020-09881-8/METRICS.
[23] H. Gamper, C. K. A. Reddy, R. Cutler, I. J. Tashev, and J. Gehrke, “Intrusive and non-intrusive perceptual speech quality assessment using a convolutional neural network,” IEEE Work. Appl. Signal Process. to Audio Acoust., vol. 2019-October, pp. 85–89, Oct. 2019, doi: 10.1109/WASPAA.2019.8937202.
[24] M. Talbi and M. Salim Bouhlel, “New Speech Compression Technique based on Filter Bank Design and Psychoacoustic Model”, doi: 10.20855/ijav.2019.24.41455.
[25] K. Kąkol, G. Korvel, and B. Kostek, “Improving Objective Speech Quality Indicators in Noise Conditions,” Stud. Comput. Intell., vol. 869, pp. 199–218, 2020, doi: 10.1007/978-3-030-39250-5_11/COVER.
[26] R. Din and A. J. Qasim, “Steganography analysis techniques applied to audio and image files,” Bull. Electr. Eng. Informatics, vol. 8, no. 4, pp. 1297–1302, Dec. 2019, doi: 10.11591/EEI.V8I4.1626.
[27] A. S. Abosinnee and Z. M. Hussain, “STATISTICAL VS. INFORMATION-THEORETIC SIGNAL PROPERTIES OVER FFT-OFDM,” J. Theor. Appl. Inf. Technol., vol. 97, p. 22, 2019, Accessed: Mar. 03, 2024. [Online]. Available: www.jatit.org
[28] A. G. Ramirez-Aristizabal and C. Kello, “EEG2Mel: Reconstructing Sound from Brain Responses to Music,” Jul. 2022, Accessed: Mar. 03, 2024. [Online]. Available: https://arxiv.org/abs/2207.13845v1
[29] L. Amaya and E. Inga, “Compressed Sensing Technique for the Localization of Harmonic Distortions in Electrical Power Systems,” Sensors 2022, Vol. 22, Page 6434, vol. 22, no. 17, p. 6434, Aug. 2022, doi: 10.3390/S22176434.
[30] P. Burrascano, A. Terenzi, S. Cecchi, M. Ciuffetti, and S. Spinsante, “A Swept-Sine-Type Single Measurement to Estimate Intermodulation Distortion in a Dynamic Range of Audio Signal Amplitudes,” IEEE Trans. Instrum. Meas., vol. 70, 2021, doi: 10.1109/TIM.2021.3077983.
[31] A. Alaei, S. M. Saghaeian Nejad, J. F. Gieras, D. Lee, and J. Ahn, “Reduction of high‐frequency injection losses, acoustic noise and total harmonic distortion in IPMSM sensorless drives,” IET Power Electron., vol. 12, no. 12, pp. 3197–3207, Oct. 2019, doi: 10.1049/IET-PEL.2018.6250.
Appendix: MATLAB Code for Audio Compression Evaluation
Description:
The MATLAB code provided below implements the evaluation of audio compression algorithms discussed in the research paper. It includes functions for loading audio files, executing compression algorithms, calculating performance metrics, and generating comparative analysis graphs.
Code Repository Link:
https://www.kaggle.com/datasets/umerijazrandhawa/matlab-code-for-audio-compression
Code Files:
Main Script Audio Compression. M: Main script to evaluate audio compression algorithms and generate comparative analysis.
Load Audio Files M: Function to load audio files from the dataset.
Compress Audio. M: Function to execute compression algorithms on audio files.
Calculate Performance Metrics. M: Function to calculate performance metrics such as Mean Squared Error, Perceptual Evaluation of Speech Quality, Structural Similarity Index, and Total Harmonic Distortion.
Generate Comparison Graphs. M: Function to generate comparative analysis graphs for performance metrics.
Compression Algorithm Functions:
mp3_compression.m
lpc_compression. m
wavelet_compression. m
subband_compression. m
Performance Metrics Functions:
mean_squared_error.m
perceptual_evaluation_of_speech_quality.m
structural_similarity_index.m
total_harmonic_distortion.m
Input Data:
The input data consists of a curated set of audio files, including "Audio1.wav" to "Audio5.wav," each representing distinctive characteristics and complexities commonly encountered in real-world scenarios.
Output:
The MATLAB code generates comparative analysis graphs illustrating the performance of different audio compression algorithms based on the evaluation metrics discussed in the research paper.
Usage: Clone or download the repository containing the MATLAB code.