
Medical Intent Classification Using Ensemble and Deep Learning Models
Keywords:
NLP, Intent Classification, Word Embedding, Sentence Transformers, Health Informatics, Transformer Models.Abstract
Introduction: Medical chatbots are innovative solutions that leverage Natural Language Processing (NLP) and Artificial Intelligence (AI) to enhance communication efficiency between healthcare providers and patients. In the realm of conversational AI, intent classification—the task of understanding a user's intent from natural language input—is both a complex and crucial aspect of the technology. This process is vital for ensuring that chatbots can accurately interpret and respond to patient queries in a meaningful and contextually appropriate manner.
Novelty Statement: This research proposes a hybrid approach that combines transformer-based embeddings with traditional deep learning models to reduce both complexity and computational cost in medical intent classification. By integrating the strengths of advanced transformer techniques with more established models, this approach aims to improve efficiency without sacrificing performance, making it more suitable for real-world healthcare applications.
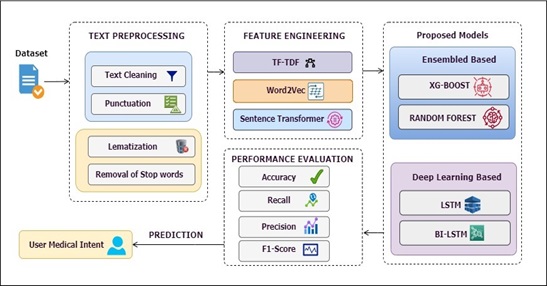
Material and Method: This study investigates the use of context-aware word embeddings, including word2vec and sentence transformers, to capture rich semantic information from medical text. To refine the unstructured data, we apply various NLP preprocessing techniques, such as text cleaning, stop word removal, and lemmatization. For classification, we utilize a combination of ensemble-based and deep learning methods, including XGBoost, Random Forest, LSTM, and Bi-LSTM. These methods are tested on real-world data from 6,662 patients, with the dataset containing 25 distinct classes.
Result and Discussion: Empirical analysis demonstrates that the Bi-LSTM model, when combined with sentence transformers, achieves an accuracy of 95.23%, outperforming state-of-the-art models reported in the relevant literature.
Concluding Remarks: This research is expected to be highly beneficial to healthcare professionals by enhancing information extraction and enabling more effective handling of patient queries.
References
C. Zeng, S. Li, Q. Li, J. Hu, and J. Hu, “A Survey on Machine Reading Comprehension—Tasks, Evaluation Metrics and Benchmark Datasets,” Applied Sciences, vol. 10, no. 21, 2020, doi: 10.3390/app10217640.
J. He, L. Peng, Y. Zhang, B. Sun, R. Xiao, and Y. Xiao, “Machine Reading Comprehension with Rich Knowledge,” Intern J Pattern Recognit Artif Intell, vol. 36, no. 05, p. 2251004, Apr. 2022, doi: 10.1142/S0218001422510041.
X. Xu, T. Tohti, and A. Hamdulla, “A Survey of Machine Reading Comprehension Methods,” in 2022 International Conference on Asian Language Processing (IALP), 2022, pp. 312–317. doi: 10.1109/IALP57159.2022.9961260.
R. G. Reddy, M. A. Sultan, E. S. Kayi, R. Zhang, V. Castelli, and A. Sil, “Answer Span Correction in Machine Reading Comprehension,” 2020, arXiv. doi: 10.48550/ARXIV.2011.03435.
R. Baradaran, R. Ghiasi, and H. Amirkhani, “A Survey on Machine Reading Comprehension Systems,” Nat Lang Eng, vol. 28, no. 6, pp. 683–732, 2022, doi: DOI: 10.1017/S1351324921000395.
J. Liu, Y. Chen, and J. Xu, “Document-level event argument linking as machine reading comprehension,” Neurocomputing, vol. 488, pp. 414–423, 2022, doi: https://doi.org/10.1016/j.neucom.2022.03.016.
F. Li, Y. Shan, X. Mao, X. Ren, X. Liu, and S. Zhang, “Multi-task joint training model for machine reading comprehension,” Neurocomputing, vol. 488, pp. 66–77, 2022, doi: https://doi.org/10.1016/j.neucom.2022.02.082.
A. Mohammadi, R. Ramezani, and A. Baraani, “A Comprehensive Survey on Multi-hop Machine Reading Comprehension Approaches,” 2022, arXiv. doi: 10.48550/ARXIV.2212.04072.
J. Liu, L. Cui, H. Liu, D. Huang, Y. Wang, and Y. Zhang, “LogiQA: A Challenge Dataset for Machine Reading Comprehension with Logical Reasoning,” 2020, arXiv. doi: 10.48550/ARXIV.2007.08124.
H. T.-T. Le, V.-D. Ho, D.-V. Nguyen, and N. L.-T. Nguyen, “Integrating Semantic Information into Sketchy Reading Module of Retro-Reader for Vietnamese Machine Reading Comprehension,” in 2022 9th NAFOSTED Conference on Information and Computer Science (NICS), 2022, pp. 53–58. doi: 10.1109/NICS56915.2022.10013390.
S. Back, S. C. Chinthakindi, A. Kedia, H. Lee, and J. Choo, “NeurQuRI: Neural Question Requirement Inspector for Answerability Prediction in Machine Reading Comprehension,” in International Conference on Learning Representations, 2020. [Online]. Available: https://openreview.net/forum?id=ryxgsCVYPr
S. Yuan et al., “Large-Scale Multi-granular Concept Extraction Based on Machine Reading Comprehension,” in The Semantic Web ISWC 2021, Springer International Publishing, 2021, pp. 93–110. doi: 10.1007/978-3-030-88361-4_6.
F. K. Alarfaj, I. Malik, H. U. Khan, N. Almusallam, M. Ramzan, and M. Ahmed, “Credit Card Fraud Detection Using State-of-the-Art Machine Learning and Deep Learning Algorithms,” IEEE Access, vol. 10, pp. 39700–39715, 2022, doi: 10.1109/ACCESS.2022.3166891.
M. Ahmed, H. Khan, T. Iqbal, F. Khaled Alarfaj, A. Alomair, and N. Almusallam, “On solving textual ambiguities and semantic vagueness in MRC based question answering using generative pre-trained transformers,” PeerJ Comput Sci, vol. 9, p. e1422, Jul. 2023, doi: 10.7717/peerj-cs.1422.
Md. A. Parwez, Mohd. Fazil, M. Arif, M. T. Nafis, and Md. R. Auwul, “Biomedical Text Classification Using Augmented Word Representation Based on Distributional and Relational Contexts,” Comput Intell Neurosci, vol. 2023, no. 1, p. 2989791, 2023, doi: https://doi.org/10.1155/2023/2989791.
L. Almazaydeh, M. Abuhelaleh, A. Al Tawil, and K. Elleithy, “Clinical Text Classification with Word Representation Features and Machine Learning Algorithms.,” International Journal of Online & Biomedical Engineering, vol. 19, no. 4, 2023.
Q. Zhang, Q. Yuan, P. Lv, M. Zhang, and L. Lv, “Research on Medical Text Classification Based on Improved Capsule Network,” Electronics (Basel), vol. 11, no. 14, 2022, doi: 10.3390/electronics11142229.
R. López, J. Tejada, and M. Alexandrov, “MEDICAL TEXTS CLASSIFICATION BASED ON KEYWORDS USING SEMANTIC INFORMATION,” Transactions on Business and Engineering Intelligent Applications, p. 64, 2014.
A. Al-Doulat, I. Obaidat, and M. Lee, “Unstructured Medical Text Classification using Linguistic Analysis: A Supervised Deep Learning Approach,” in 2019 IEEE/ACS 16th International Conference on Computer Systems and Applications (AICCSA), 2019, pp. 1–7. doi: 10.1109/AICCSA47632.2019.9035282.
L. Yao, C. Mao, and Y. Luo, “Clinical text classification with rule-based features and knowledge-guided convolutional neural networks,” BMC Med Inform Decis Mak, vol. 19, no. 3, p. 71, 2019, doi: 10.1186/s12911-019-0781-4.
C. Mao, Q. Zhu, R. Chen, and W. Su, “Automatic medical specialty classification based on patients’ description of their symptoms,” BMC Med Inform Decis Mak, vol. 23, no. 1, p. 15, 2023, doi: 10.1186/s12911-023-02105-7.
E. Richard and B. Reddy, “Text Classification for Clinical Trial Operations: Evaluation and Comparison of Natural Language Processing Techniques,” Ther Innov Regul Sci, vol. 55, no. 2, pp. 447–453, 2021, doi: 10.1007/s43441-020-00236-x.
H. Zhou, “Research of Text Classification Based on TF-IDF and CNN-LSTM,” J Phys Conf Ser, vol. 2171, no. 1, p. 12021, Jan. 2022, doi: 10.1088/1742-6596/2171/1/012021.
M. Ahmed, H. U. Khan, M. A. Khan, U. Tariq, and S. Kadry, “Context-Aware Answer Selection in Community Question Answering Exploiting Spatial Temporal Bidirectional Long Short-Term Memory,” ACM Trans. Asian Low-Resour. Lang. Inf. Process., Jun. 2023, doi: 10.1145/3603398.
M. Ahmed, H. U. Khan, S. Iqbal, and Q. Althebyan, “Automated Question Answering based on Improved TF-IDF and Cosine Similarity,” in 2022 Ninth International Conference on Social Networks Analysis, Management and Security (SNAMS), 2022, pp. 1–6. doi: 10.1109/SNAMS58071.2022.10062839.
S. Iqbal, R. Khan, H. U. Khan, F. K. Alarfaj, A. M. Alomair, and M. Ahmed, “Association Rule Analysis-Based Identification of Influential Users in the Social Media,” 2022.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2024 50sea

This work is licensed under a Creative Commons Attribution 4.0 International License.















