
Exploring Computational Models for Syntactic Analysis in Sindhi Part-of-Speech Tagging
DOI:
https://doi.org/10.33411/IJIST/1702Keywords:
Hidden Markov Model, Conditional Random Fields, Support Vector Machine, Part-of-Speech Tagging, Natural Language ProcessingAbstract
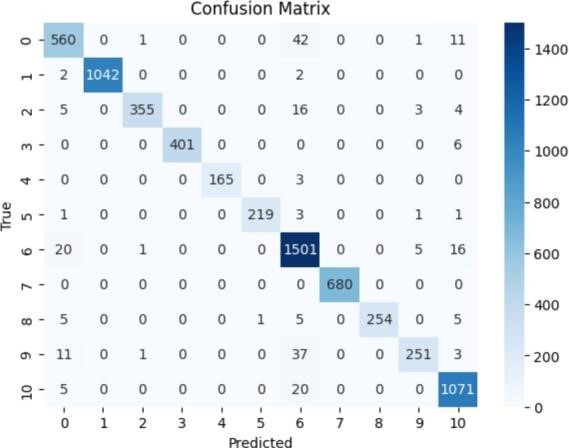
Identifying part-of-speech tags is basically a crucial aspect of language tagging. It facilitates the introduction of very important applications, for example, machine translation and sentiment analysis. Low-resource languages typically get deprived of these resources mainly because of their complex morphology, scarcity of annotated datasets, and difficulties they present when writing from right to left. This paper tries to tackle these issues by thoroughly going over the different POS tagging methods to set a reliable benchmark for performance assessment of the Sindhi language. We conducted experiments using a well-balanced and standardized dataset with five different models, i.e., Hidden Markov Models (HMM), Bidirectional Long Short-term Memory (BiLSTM), Naive Bayes, Support Vector Machines (SVM), and Conditional Random Fields (CRF). Results revealed that Naive Bayes was the best among others, as it used morphological suffix patterns effectively to reach a level of accuracy of 97%. CRF and HMM both followed closely behind Naive Bayes and secured accuracy results of 92.29% and 93.37%, respectively. SVM encountered difficulties with repetitive tags, resulting in a lower accuracy of 84.64%, which gave it a lower accuracy of 84.64%, the The BiLSTM model was capable of using contextual information, thus reaching the accuracy of 91.32%. These results indicate that, in fact, in the case of languages with regular morphological patterns, simple statistical methods might be highly effective even if neural networks were more advanced. This paper lays a strong groundwork for the future progress of natural language processing for Sindhi and other minor languages.
References
J. K. Wazir Ali, Zenglin Xu, “SiPOS: A Benchmark Dataset for Sindhi Part-of-Speech Tagging,” ACL Anthol., 2021, [Online]. Available: https://aclanthology.org/2021.ranlp-srw.4/
S. H. Adnan Ali Memon, “Parts-of-speech tagger for Sindhi language using deep neural network architecture,” Mehran Univ. Res. J. Eng. Technol., vol. 43, no. 3, p. 47, 2024, [Online]. Available: https://www.researchgate.net/publication/382162774_Parts-of-speech_tagger_for_Sindhi_language_using_deep_neural_network_architecture
N. A.-T. Wasan AlKhwiter, “Part-of-speech tagging for Arabic tweets using CRF and Bi-LSTM,” Comput. Speech Lang., vol. 65, p. 101138, 2021, [Online]. Available: https://www.sciencedirect.com/science/article/abs/pii/S0885230820300711
N. A. S. S. R. Saira Baby Farooqui, “Architecture of Parts of speech Tagger in Sindhi Language,” J. Inf. Commun. btn btn-dark btn-xs btn-round), vol. 16, no. 2.
I. A. OLGA LYASHEVSKAYA, “An Hmm-Based Pos Tagger for Old Church Slavonic,” Jazykoved. časopis, vol. 72, 2021, [Online]. Available: https://www.hse.ru/data/2025/06/19/1989024782/Статья 3.pdf
Wazir Ali, Rajesh Kumar, “Neural Joint Model for Part-of-Speech Tagging and Entity Extraction,” ACM Int. Conf. Proceeding Ser., 2021, [Online]. Available: https://dl.acm.org/doi/10.1145/3457682.3457718
A. Pradhan and A. Yajnik, “Parts-of-speech tagging of Nepali texts with Bidirectional LSTM, Conditional Random Fields and HMM,” Multimed. Tools Appl. 2023 834, vol. 83, no. 4, pp. 9893–9909, Jun. 2023, doi: 10.1007/s11042-023-15679-1.
S. M. Z. Minnaa Ahmad, Muhammad Shoaib Tahir, “A Comparative Study of Manual and Automated POS Tagging: Insights into Accuracy, Scalability, and Application Contexts,” Pakistan Res. J. Soc. Sci., vol. 3, no. 3, 2024, [Online]. Available: https://prjss.com/index.php/prjss/article/view/156/156
S. Ullah, “A Deep Learning-Based Approach for Part of Speech (PoS) Tagging in the Pashto Language,” IEEE Access, vol. 12, pp. 86355–86364, 2024, [Online]. Available: https://ieeexplore.ieee.org/document/10552703
Johnatan E. Bonilla, “Spoken Spanish PoS tagging: gold standard dataset,” Lang. Resour. Eval., vol. 59, pp. 983–1012, 2025, [Online]. Available: https://link.springer.com/article/10.1007/s10579-024-09751-x
E. L. L. Aiom Minnette Mitri, “Probing a pretrained RoBERTa on Khasi language for POS tagging,” Nat. Lang. Process, 2024, [Online]. Available: https://www.cambridge.org/core/journals/natural-language-processing/article/probing-a-pretrained-roberta-on-khasi-language-for-pos-tagging/F4A8B8DA809F4921D60D5BBAAF2F9A22
Jimson Paulo Layacan, Isaiah Edri W. Flores, Katrina Bernice M. Tan, Ma. Regina E. Estuar, Jann Railey E. Montalan, Marlene M. De Leon, “Zero-shot Cross-lingual POS Tagging for Filipino,” ACL Anthol., 2024, [Online]. Available: https://aclanthology.org/2024.fieldmatters-1.9/
Zeno Vandenbulcke, Lukas Vermeire, Miryam de Lhoneux, “Recipe for Zero-shot POS Tagging: Is It Useful in Realistic Scenarios?,” ACL Anthol., 2024, [Online]. Available: https://aclanthology.org/2024.mrl-1.9/
S. F. Latofat Bobojonova, Arofat Akhundjanova, Phil Sidney Ostheimer, “BBPOS: BERT-based Part-of-Speech Tagging for Uzbek,” ACL Anthol., 2025, [Online]. Available: https://aclanthology.org/2025.loreslm-1.23/
Muhammad Nabeel Asghar, “A Novel Parts of Speech (POS) Tagset for morphological, syntactic and lexical annotations of Saraiki language,” J. Appl. Emerg. Sci., vol. 11, no. 1, p. 77, 2021, doi: 10.36785/jaes.111459.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 50sea

This work is licensed under a Creative Commons Attribution 4.0 International License.















