
UM-MDAS: A Unified Model Framework for Multi-Document Abstractive Summarization
Keywords:
Multi-Document Summarization, SBERT, PEGASUS, NLP, Deep LearningAbstract
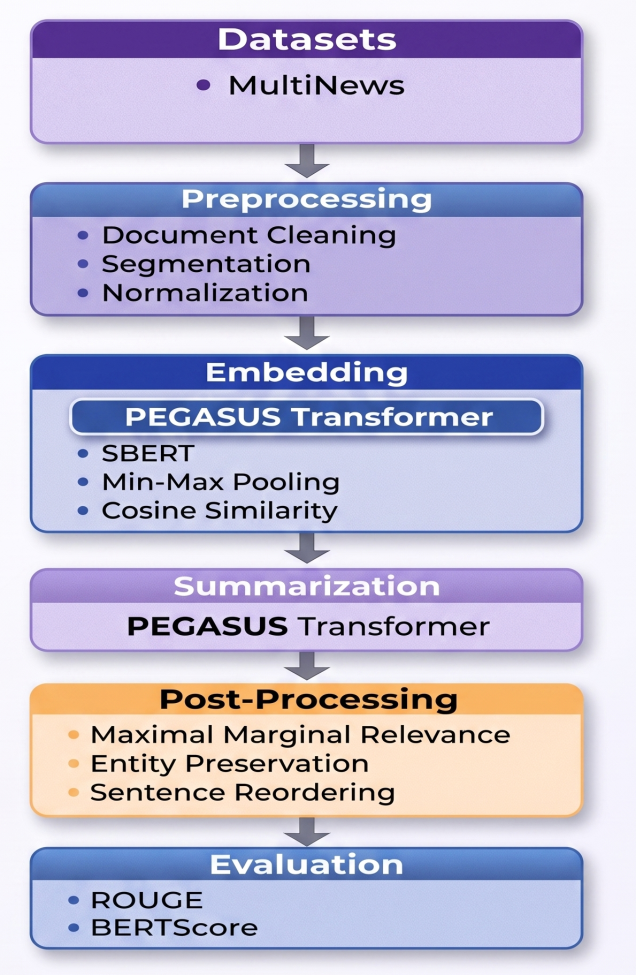
The volume of information across diverse sources has been increasing rapidly, and thus, there has been a need for effective multi-document summarization systems. Multi-Document Abstractive Summarization (MDAS) aims to generate concise and coherent summaries that capture common core ideas between related documents. Despite recent improvements in transformer-based models in the transformer-based models, the current methodologies of MDAS still struggle with cross-document redundancy, inconsistent content selection, and the inability to control redundancy in the salience of a summary. The article introduces a framework, UM-MDAS, which is a unified and modular architecture of multi-document abstractive summarization to overcome these challenges with a structured pipeline architecture. The framework builds sentence-level semantic representations based on SBERT and combines the representations into document-level representations through min-max pooling to identify salient and extreme semantic features. The cosine similarity is used to measure semantic relevance and eliminate redundancy across document clusters, whereas the abstractive summary generation is done through the PEGASUS sequence-to-sequence model. The experiments carried out with MultiNews data indicate that UM-MDAS enhances semantic coverage, fluency, and coherence. Evaluation results show ROUGE-1 (53.83), ROUGE-2 (21.00), ROUGE-L (23.54), and BERTScore (86.41), indicating that the proposed framework performs well in capturing both surface-level and contextual similarities. The article introduces a framework, UM-MDAS, which is a unified and modular architecture of multi-document abstractive summarization to overcome these challenges with a structured pipeline architecture.
References
“(PDF) Writing in English as A Foreign Language: How Literary Reading Helps Students Improve Their Writing Skills: A Descriptive Study.” Accessed: Apr. 21, 2026. [Online]. Available: https://www.researchgate.net/publication/364960065_Writing_in_English_as_A_Foreign_Language_How_Literary_Reading_Helps_Students_Improve_Their_Writing_Skills_A_Descriptive_Study
Yasser Alharbi, Sarwar Shah Khan, “Classifying Multi-Lingual Reviews Sentiment Analysis in Arabic and English Languages Using the Stochastic Gradient Descent Model,” Comput. Mater. Contin., vol. 83, no. 1, pp. 1275–1290, 2025, doi: https://doi.org/10.32604/cmc.2025.061490.
B. Khan, Z. A. Shah, M. Usman, I. Khan and B. Niazi, “Exploring the Landscape of Automatic Text Summarization: A Comprehensive Survey,” IEEE Access, vol. 11, pp. 109819–109840, 2023, doi: 10.1109/ACCESS.2023.3322188.
M. Azam et al., “Current Trends and Advances in Extractive Text Summarization: A Comprehensive Review,” IEEE Access, vol. 13, pp. 28150–28166, 2025, doi: 10.1109/ACCESS.2025.3538886.
Congbo Ma, Wei Emma Zhang, Mingyu Guo, Hu Wang, Quan Z. Sheng, “Multi-document Summarization via Deep Learning Techniques: A Survey,” arXiv:2011.04843, 2021, [Online]. Available: https://arxiv.org/abs/2011.04843
Jinming Zhao, Ming Liu, Longxiang Gao, Yuan Jin, Lan Du, He Zhao, He Zhang, Gholamreza Haffari, “SummPip: Unsupervised Multi-Document Summarization with Sentence Graph Compression,” arXiv:2007.08954, 2020, [Online]. Available: https://arxiv.org/abs/2007.08954
Xiaodong Yan, Yiqin Wang, “Unsupervised Graph-Based Tibetan Multi-Document Summarization,” Comput. Mater. Contin., vol. 73, no. 1, pp. 1769–1781, 2022, doi: https://doi.org/10.32604/cmc.2022.027301.
“Leveraging Graph to Improve Abstractive Multi-Document Summarization - ACL Anthology.” Accessed: Apr. 21, 2026. [Online]. Available: https://aclanthology.org/2020.acl-main.555/
J. Shah, M. M. Danyal, S. S. Khan, and A. Khan, “Enhancing News Summarization Based on Advanced Deep Learning Models Using the BBC News Dataset,” Infosys Sci. Found. Ser. Math. Sci., vol. Part F1395, pp. 313–330, 2026, doi: 10.1007/978-981-95-2212-5_20.
Sohail Muhammad, Muzammil Khan, “A Hybrid Query-Based Extractive Text Summarization Based on K-Means and Latent Dirichlet Allocation Techniques,” J. Artif. Intell., vol. 6, no. 3, pp. 193–209, 2024, doi: 10.32604/jai.2024.052099.
“Abstractive Multi-Document Summarization via Joint Learning with Single-Document Summarization - ACL Anthology.” Accessed: Apr. 21, 2026. [Online]. Available: https://aclanthology.org/2020.findings-emnlp.231/
“Multi-Granularity Interaction Network for Extractive and Abstractive Multi-Document Summarization - ACL Anthology.” Accessed: Apr. 21, 2026. [Online]. Available: https://aclanthology.org/2020.acl-main.556/
“Entity-Aware Abstractive Multi-Document Summarization - ACL Anthology.” Accessed: Apr. 21, 2026. [Online]. Available: https://aclanthology.org/2021.findings-acl.30/
Rawan Alsultan, Alaa Sagheer, Hala Hamdoun, Lamya Alshamlan & Latifah Alfadhli, “PEGASUS-XL with saliency-guided scoring and long-input encoding for multi-document abstractive summarization,” Sci. Rep., 2025, [Online]. Available: https://www.nature.com/articles/s41598-025-11062-2
P. Singh, P. Kashetty, A. S. R. T. Reddy, G. S. Teja, and V. Anusha, “Automated News Summarization using Transformers,” ISML 2024 - Intell. Syst. Mach. Learn. Conf., pp. 693–697, 2024, doi: 10.1109/ISML60050.2024.11007399.
Wen Xiao, Iz Beltagy, Giuseppe Carenini, Arman Cohan, “PRIMERA: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization,” arXiv:2110.08499, 2022, [Online]. Available: https://arxiv.org/abs/2110.08499
“AI-driven Generation of News Summaries Leveraging GPT and Pegasus Summarizer for Efficient Information Extraction - EUDL.” Accessed: Apr. 21, 2026. [Online]. Available: https://eudl.eu/doi/10.4108/eai.18-12-2023.2348180
S. S. Khan and Y. Alharbi, “Sentiment analysis of movie review classifications using deep learning approaches,” Int. J. Adv. Appl. Sci., vol. 11, no. 8, pp. 146–157, Aug. 2024, doi: 10.21833/IJAAS.2024.08.016.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, “Attention Is All You Need,” arXiv:1706.03762, 2017, [Online]. Available: https://arxiv.org/abs/1706.03762
Nils Reimers, Iryna Gurevych, “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,” arXiv:1908.10084, 2019, [Online]. Available: https://arxiv.org/abs/1908.10084
Eman Daraghmi, Lour Atwe, “A Comparative Study of PEGASUS, BART, and T5 for Text Summarization Across Diverse Datasets,” Futur. Internet, vol. 17, no. 9, p. 389, 2025, doi: https://doi.org/10.3390/fi17090389.
“PELMS: Pre-training for Effective Low-Shot Multi-Document Summarization - ACL Anthology.” Accessed: Apr. 21, 2026. [Online]. Available: https://aclanthology.org/2024.naacl-long.423/
“On the Trade-off between Redundancy and Cohesiveness in Extractive Summarization | Journal of Artificial Intelligence Research.” Accessed: Apr. 21, 2026. [Online]. Available: https://jair.org/index.php/jair/article/view/15191
Joshua Maynez, Shashi Narayan, Bernd Bohnet, Ryan McDonald, “On Faithfulness and Factuality in Abstractive Summarization,” arXiv:2005.00661, 2020, [Online]. Available: https://arxiv.org/abs/2005.00661
Mousumi Akter, Naman Bansal, “Assessing the effectiveness of ROUGE as unbiased metric in Extractive vs. Abstractive summarization techniques,” J. Comput. Sci., vol. 87, p. 102571, 2025, doi: https://doi.org/10.1016/j.jocs.2025.102571.
Bianca Steffes, Luise Burger, “On evaluating legal summaries with ROUGE,” 19th Int. Conf. Artif. Intell. Law, ICAIL 2023 - Proc. Conf., 2023, [Online]. Available: https://dl.acm.org/doi/10.1145/3594536.3595150
K. Mrinalini, P. Vijayalakshmi, and N. Thangavelu, “SBSim: A Sentence-BERT Similarity-Based Evaluation Metric for Indian Language Neural Machine Translation Systems,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 30, pp. 1396–1406, 2022, doi: 10.1109/TASLP.2022.3161160.
“Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model - ACL Anthology.” Accessed: Apr. 21, 2026. [Online]. Available: https://aclanthology.org/P19-1102/
R. Pasunuru, M. Liu, M. Bansal, S. Ravi, and M. Dreyer, “Efficiently summarizing text and graph encodings of multi-document clusters,” in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021, pp. 4768–4779.
“Error Analysis of using BART for Multi-Document Summarization: A Study for English and German Language - ACL Anthology.” Accessed: Apr. 21, 2026. [Online]. Available: https://aclanthology.org/2021.nodalida-main.43/
M. M. Danyal, A. Khalid, S. shah Khan, S. Ullah, H. Jan, and D. Khan, “Sentiment-Aware Summary Generation for User Reviews Using Deep Learning Models,” VFAST Trans. Softw. Eng., vol. 13, no. 3, pp. 325–339, 2025.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 50sea

This work is licensed under a Creative Commons Attribution 4.0 International License.















