
What have you read? based Multi-Document Summarization
Keywords:
Data mining, Text mining, Text summarization, Topic Signature, Density peak, Update SummarizationAbstract
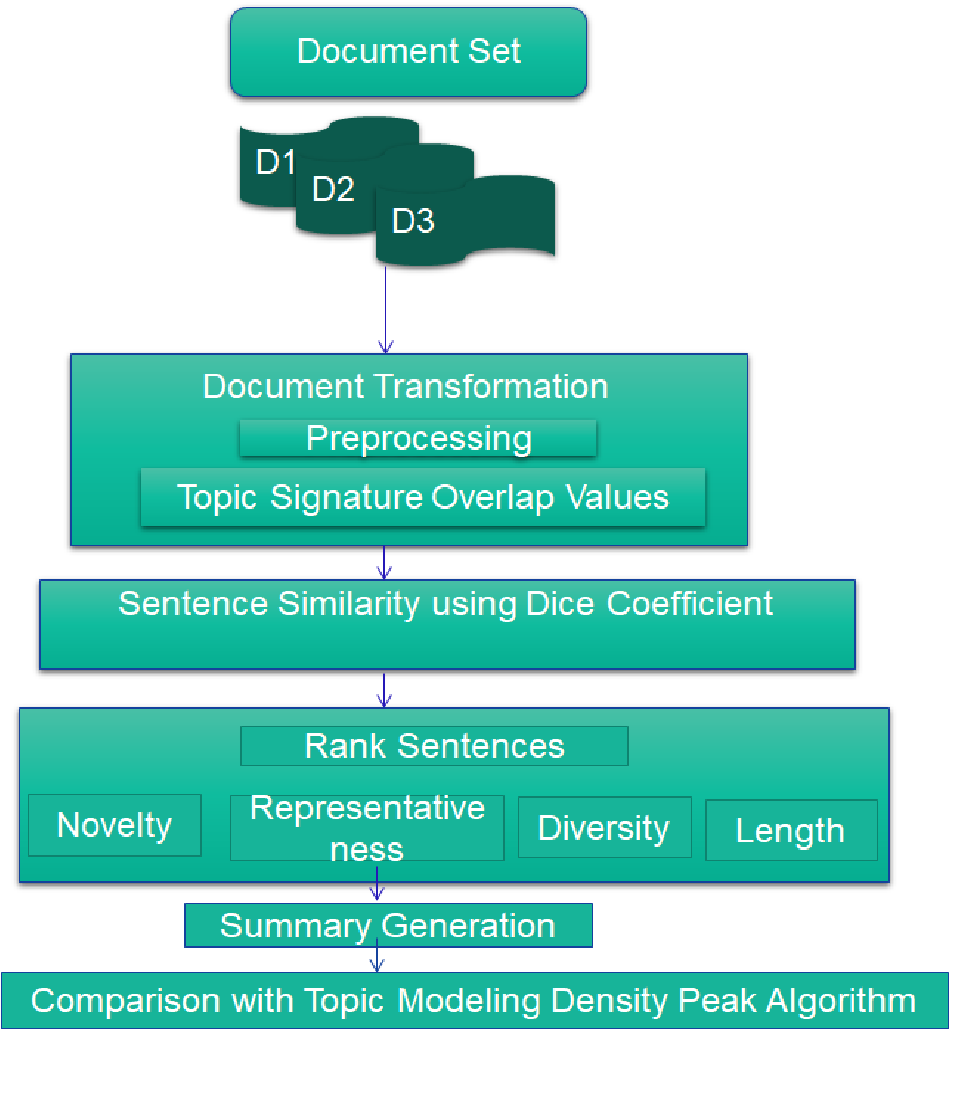
Due to the tremendous amount of data available today, extracting essential information from such a large volume of data is quite tough. Particularly in the case of text documents, which need a significant amount of time from the user to read the material and extract useful information. The major problem is identifying the user's relevant documents, removing the most significant pieces of information, determining document relevancy, excluding extraneous information, reducing details, and generating a compact, consistent report. For all these issues, we proposed a novel technique that solves the problem of extracting important information from a huge amount of text data and using previously read documents to generate summaries of new documents. Our technique is more focused on extracting topics (also known as topic signatures) from the previously read documents and then selecting the sentences that are more relevant to these topics based on update summary generation. Besides this, the concept of overlapping value is used that digs out the meaningful words and word similarities. Another thing that makes our work better is the Dice Coefficient which measures the intersection of words between document sets and helps to eliminate redundancy. The summary generated is based on more diverse and highly representative sentences with an average length. Empirically, we have observed that our proposed novel technique performed better with baseline competitors on the real-world TAC2008 dataset.
References
R. Li and H. Shindo, "A hierarchical tree model for update summarization," Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 9022, pp. 660–665, 2015, doi: 10.1007/978-3-319-16354-3_72.
K. M. Svore, L. Vanderwende, and C. J. C. Burges, "Enhancing single-document summarization by combining RankNet and third-party sources," EMNLP-CoNLL 2007 - Proc. 2007 Jt. Conf. Empir. Methods Nat. Lang. Process. Comput. Nat. Lang. Learn., no. June, pp. 448–457, 2007.
L. Bing, P. Li, Y. Liao, W. Lam, W. Guo, and R. J. Passonneau, "Abstractive Multi-Document Summarization via Phrase Selection and Merging," ACL-IJCNLP 2015 - 53rd Annu. Meet. Assoc. Comput. Linguist. 7th Int. Jt. Conf. Nat. Lang. Process. Asian Fed. Nat. Lang. Process. Proc. Conf., vol. 1, pp. 1587–1597, Jun. 2015, doi: 10.48550/arxiv.1506.01597.
R. O. and S. W. Anjum. M. S, Mumtaz. S, "Heart Attack Risk Prediction with Duke Treadmill Score with Symptoms using Data Mining," I nternational J. Innov. Sci. Technol., vol. 3, no. 4, pp. 174–185, 2021.
C. Li, Y. Liu, and L. Zhao, "Improving update summarization via supervised ILP and sentence reranking," NAACL HLT 2015 - 2015 Conf. North Am. Chapter Assoc. Comput. Linguist. Hum. Lang. Technol. Proc. Conf., no. August 2016, pp. 1317–1322, 2015, doi: 10.3115/v1/n15-1145.
Y. Song, W. Ng, K. W. T. Leung, and Q. Fang, "SFP-Rank: significant frequent pattern analysis for effective ranking," Knowl. Inf. Syst., vol. 43, no. 3, pp. 529–553, 2015, doi: 10.1007/s10115-014-0738-y.
Q. M. A. and M. . Kiran. I, Siddique. Z, Butt. A. R, Mudassir. A. I, "Towards Skin Cancer Classification Using Machine Learning and Deep Learning Algorithms: A Comparison," I nternational J. Innov. Sci. Technol., vol. 3, no. special issue, pp. 110–118, 2021.
Y. Zhang, Y. Xia, Y. Liu, and W. Wang, "Clustering sentences with density peaks for multi-document summarization," NAACL HLT 2015 - 2015 Conf. North Am. Chapter Assoc. Comput. Linguist. Hum. Lang. Technol. Proc. Conf., no. January, pp. 1262–1267, 2015, doi: 10.3115/v1/n15-1136.
W. Tong, S. Liu, and X. Z. Gao, "A density-peak-based clustering algorithm of automatically determining the number of clusters," Neurocomputing, vol. 458, pp. 655–666, Oct. 2021, doi: 10.1016/J.NEUCOM.2020.03.125.
R. Srivastava, P. Singh, K. P. S. Rana, and V. Kumar, "A topic modeled unsupervised approach to single document extractive text summarization," Knowledge-Based Syst., vol. 246, Jun. 2022, doi: 10.1016/J.KNOSYS.2022.108636.
X. Tao, R. Wang, R. Chang, C. Li, R. Liu, and J. Zou, "Spectral clustering algorithm using density-sensitive distance measure with global and local consistencies," Knowledge-Based Syst., vol. 170, pp. 26–42, Apr. 2019, doi: 10.1016/J.KNOSYS.2019.01.026.
X. Tao et al., "Density peak clustering using global and local consistency adjustable manifold distance," Inf. Sci. (Ny)., vol. 577, pp. 769–804, Oct. 2021, doi: 10.1016/J.INS.2021.08.036.
K. Sindhu and K. Seshadri, "Text Summarization: A Technical Overview and Research Perspectives," Handb. Intell. Comput. Optim. Sustain. Dev., pp. 261–286, Feb. 2022, doi: 10.1002/9781119792642.CH13.
D. Cheng, J. Huang, S. Zhang, X. Zhang, and X. Luo, "A Novel Approximate Spectral Clustering Algorithm with Dense Cores and Density Peaks," IEEE Trans. Syst. Man, Cybern. Syst., vol. 52, no. 4, pp. 2348–2360, Apr. 2022, doi: 10.1109/TSMC.2021.3049490.
Z. Liang and P. Chen, "An automatic clustering algorithm based on the density-peak framework and Chameleon method," Pattern Recognit. Lett., vol. 150, pp. 40–48, Oct. 2021, doi: 10.1016/J.PATREC.2021.06.017.
A. Rodriguez and A. Laio, "Clustering by fast search and find of density peaks," Science (80-. )., vol. 344, no. 6191, pp. 1492–1496, Jun. 2014, doi: 10.1126/SCIENCE.1242072/SUPPL_FILE/RODRIGUEZ.SM.PDF.
N. R. Mabroukeh and C. I. Ezeife, "A taxonomy of sequential pattern mining algorithms," ACM Comput. Surv., vol. 43, no. 1, Nov. 2010, doi: 10.1145/1824795.1824798.
C. Mallick, A. K. Das, M. Dutta, A. K. Das, and A. Sarkar, Graph-based text summarization using modified TextRank, vol. 758, no. August. Springer Singapore, 2018. doi: 10.1007/978-981-13-0514-6_14.
Published
How to Cite
Issue
Section
License
Copyright (c) 2022 50sea

This work is licensed under a Creative Commons Attribution 4.0 International License.















