
A Deep Learning Approach to Semantic Clarity in Urdu Translations of the Holy Quran
DOI:
https://doi.org/10.33411/ijist/202571259271Keywords:
Word Sense Disambiguation (WSD), Urdu Quran Translation , Multilingual BERT, Deep Learning in Linguistics, Natural Language ProcessingAbstract
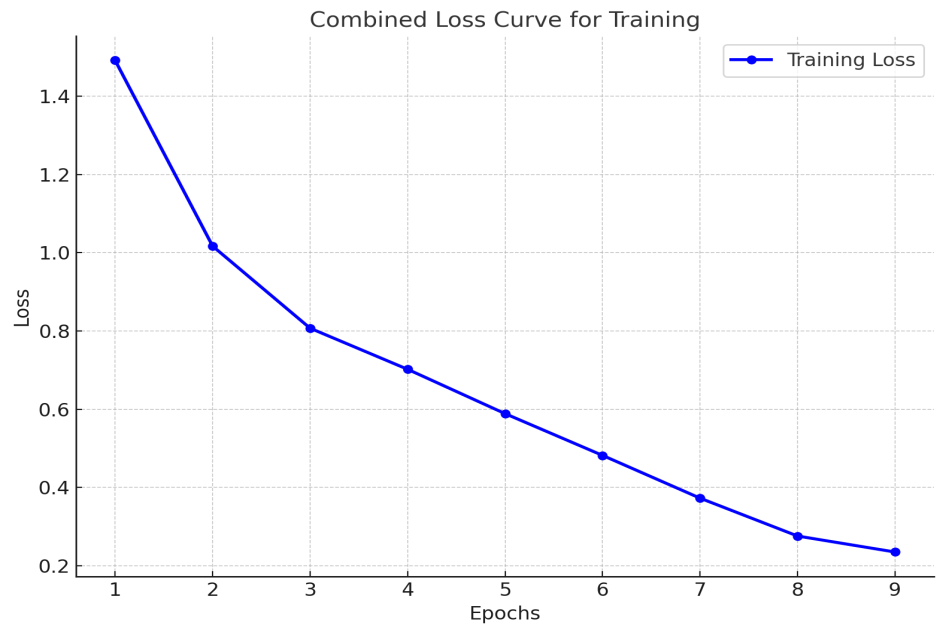
The Holy Quran holds profound significance from both religious and linguistic perspectives yet its Urdu translations face difficulties in preserving the original meaning because of ambiguous words which create interpretation challenges for speakers and listeners. This research tackles translation ambiguity in the Urdu translations of the Holy Quran authored by Maulana Abul A’ala Maududi and Fateh Muhammad Jalandhry by applying Word Sense Disambiguation methods with deep learning algorithms. A model based on multilingual BERT identifies ambiguous word senses for Surah Al-Baqarah in particular. The dataset features Surah Al-Baqarah's complete Urdu translation together with a Sense Inventory that contains 3 to 8 senses for 50 frequently used Urdu ambiguous words which are collected from GitHub repository. Sequence classification frameworks within BERT receive contextual embeddings during fine-tuning. The evaluation framework includes the determination of F1 scores alongside confusion matrix analysis and classification report assessment. The model achieved an F1-score of 0.82 when identifying the most frequent sense while reaching an average F1-score of 0.62 across eight predefined sense labels. A sense prediction system functions to improve word sense matching thereby leading to more precise translations. The proposed research makes significant contributions to computational linguistics and Quranic studies by delivering an expandable method that solves word sense ambiguity while offering important insights to help translators and scholars improve their understanding of how context affects meaning within translated texts.
References
S. K. and R. Nassar, “EnhancedBERT: A feature-rich ensemble model for Arabic word sense disambiguation with statistical analysis and optimized data collection,” J. King Saud Univ.-Comput. Inf. Sci, vol. 36, no. 1, p. 101911, 2024.
and T. J. S. P.Jha, S. Agarwal, A. Abbas, “A novel unsupervised graph-based algorithm for Hindi word sense disambiguation,” SN Comput. Sci, vol. 4, no. 5, p. 675, 2023.
and P. R. J. Shafi, H. R. Iqbal, R. M. A. Nawab, “UNLT: Urdu Natural Language Toolkit,” Nat. Lang. Eng, vol. 29, no. 4, pp. 942–977, 2023.
and M. S. A.Saeed, R. M. A. Nawab, “Investigating the feasibility of deep learning methods for Urdu word sense disambiguation,” Trans. Asian Low-Resour. Lang. Inf. Process, vol. 21, no. 2, pp. 1–16, 2021.
and X. Y. G. C. X. Zhang, Y. L. Shao, “Word sense disambiguation based on RegNet with efficient channel attention and dilated convolution,” IEEE Access, vol. 11, pp. 130733–130742, 2023.
and N. K. R. N. Tyagi, S. Chakraborty, A. Kumar, “Word sense disambiguation models emerging trends: A comparative analysis,” J. Phys. Conf. Ser., vol. 2161, no. 1, p. 012035, 2022.
and N. H. M. F.Ullah, A. Saeed, “Comparison of pre-trained vs custom-trained word embedding models for word sense disambiguation,” Adv. Distrib. Comput. Artif. Intell. J., vol. 12, no. 1, pp. e31084–e31084, 2023.
and X. H. L. Huang, C. Sun, X. Qiu, “GlossBERT: BERT for word sense disambiguation with gloss knowledge,” arXiv Prepr., 2019.
R. Saidi, et al., “WSDTN: A Novel Dataset for Arabic Word Sense Disambiguation,” Int. Conf. Comput. Collect. Intell., 2023.
M. Alian and A. Awajan, “Arabic Word Sense Disambiguation Using Sense Inventories,” Int. J. Inf. Technol., vol. 15, no. 2, pp. 735–744, 2023.
B. Abdelaali and Y. Tlili-Guiassa, “Swarm Optimization for Arabic Word Sense Disambiguation Based on English Pre-Trained Word Embeddings,” “5th Int. Symp. Informatics its Appl. (ISIA)”, IEEE, 2022.
M. A. Abderrahim and M. E.-A. Abderrahim, “Arabic Word Sense Disambiguation for Information Retrieval,” Trans. Asian Low-Resource Lang. Inf. Process., vol. 21, no. 4, pp. 1–19, 2022.
“Tanzil Project, Tanzil Quran Text, Available: https://tanzil.net/trans/.”.
“GitHub repository, Available: https://github.com/alisaeed007/UAW-WSD-18-Corpus.”.
P. Saeed, A., Nawab, R. M. A., Stevenson, M., & Rayson, “A sense annotated corpus for all-words Urdu word sense disambiguation,” ACM Trans. Asian Low-Resource Lang. Inf. Process., vol. 18, no. 4, pp. 1–19, 2019.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 50SEA

This work is licensed under a Creative Commons Attribution 4.0 International License.















