
Robust Dysarthric Speech Transcription via Transformer-Based Whisper ASR: Spectral-Temporal Modeling for Impaired Articulation
DOI:
https://doi.org/10.33411/IJIST/1786Keywords:
Dysarthric Speech Recognition, Transformer- Based ASR, OpenAI Whisper, Spectral-Temporal Speech Modeling, Phoneme Distortion Analysis, Linguistic Sensitivity AnalysisAbstract
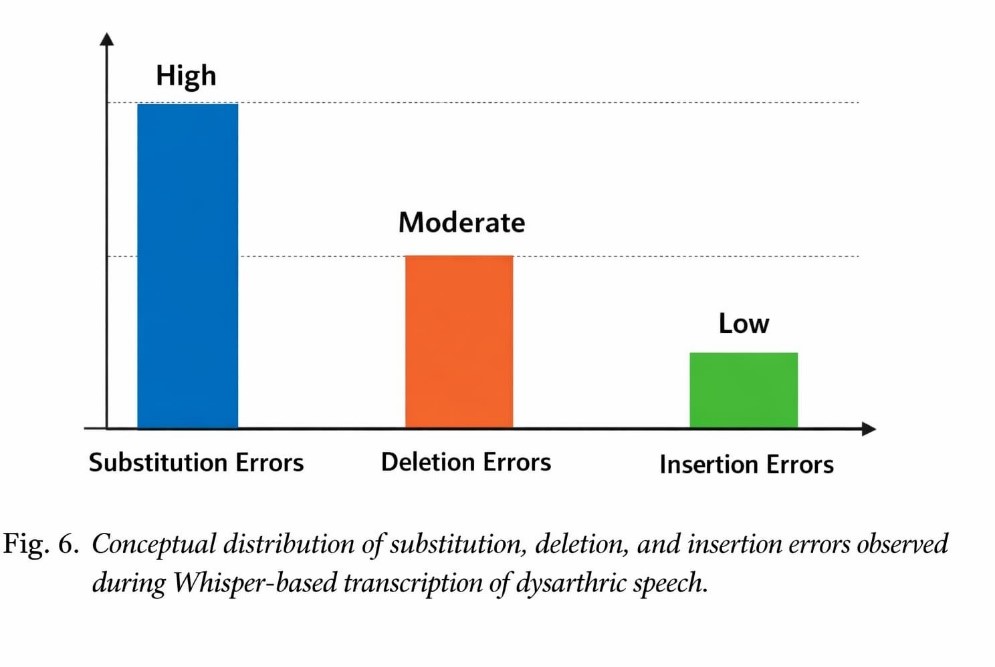
Automatic transcription of dysarthric speech remains a significant challenge due to slurred articulation, phonetic distortions, and variability in speech clarity caused by neuromuscular impairments. In this study, we leverage OpenAI’s Whisper, an encoder–decoder ASR model, to transcribe dysarthric speech from the TORGO dataset, using a carefully selected subset of 100 audio files (50 dysarthric and 50 normal speech recordings), forming 49-word pairs for evaluation. Audio recordings were preprocessed to standardize sampling rate and format, and speech representations were extracted using log-Mel spectrograms, enabling robust representation of spectral and temporal patterns despite impaired articulation. The proposed Whisper model achieved an average Word Error Rate (WER) of 1.30 errors per word, with substitution errors dominating, followed by deletion and insertion errors. Variability analyses (box plots and WER histograms) demonstrate consistent transcription performance across different dysarthric speech samples. Words with clearer articulation or prolonged phonation were transcribed more accurately, while severely distorted words contributed to higher error rates. These results provide strong quantitative evidence of Whisper’s robustness, demonstrating its capability to handle a wide range of dysarthric speech patterns and establishing its effectiveness as a reliable tool for dysarthric speech recognition in real-world ASR applications.
References
D. Wang et al., “End-to-end voice conversion via cross-modal knowledge distillation for dysarthric speech reconstruction,” ICASSP, IEEE Int. Conf. Acoust. Speech Signal Process. - Proc., vol. 2020-May, pp. 7744–7748, May 2020, doi: 10.1109/ICASSP40776.2020.9054596.
Xurong Xie, Rukiye Ruzi, Xunying Liu, Lan Wang, “Variational Auto-Encoder Based Variability Encoding for Dysarthric Speech Recognition,” arXiv:2201.09422, 2022, [Online]. Available: https://arxiv.org/abs/2201.09422
Xueyuan Chen, Dongchao Yang, Dingdong Wang, Xixin Wu, Zhiyong Wu, Helen Meng, “CoLM-DSR: Leveraging Neural Codec Language Modeling for Multi-Modal Dysarthric Speech Reconstruction,” arXiv:2406.08336, 2024, [Online]. Available: https://arxiv.org/abs/2406.08336
Wing-Zin Leung, Mattias Cross, Anton Ragni, Stefan Goetze, “Training Data Augmentation for Dysarthric Automatic Speech Recognition by Text-to-Dysarthric-Speech Synthesis,” arXiv:2406.08568, 2024, [Online]. Available: https://arxiv.org/abs/2406.08568
Yuejiao Wang, Xixin Wu, Disong Wang, Lingwei Meng, Helen Meng, “UNIT-DSR: Dysarthric Speech Reconstruction System Using Speech Unit Normalization,” arXiv:2401.14664, 2024, [Online]. Available: https://arxiv.org/abs/2401.14664
Mohammad Soleymanpour, Michael T. Johnson, Rahim Soleymanpour, Jeffrey Berry, “Accurate synthesis of Dysarthric Speech for ASR data augmentation,” arXiv:2308.08438, 2023, [Online]. Available: https://arxiv.org/abs/2308.08438
B. Abibullaev, A. Keutayeva, and A. Zollanvari, “Deep Learning in EEG-Based BCIs: A Comprehensive Review of Transformer Models, Advantages, Challenges, and Applications,” IEEE Access, vol. 11, pp. 127271–127301, 2023, doi: 10.1109/ACCESS.2023.3329678.
F. Rudzicz, A. K. Namasivayam, and T. Wolff, “The TORGO database of acoustic and articulatory speech from speakers with dysarthria,” Lang. Resour. Eval. 2011 464, vol. 46, no. 4, pp. 523–541, Mar. 2011, doi: 10.1007/s10579-011-9145-0.
Zhaopeng Qian, Kejing Xiao & Chongchong Yu, “A survey of technologies for automatic Dysarthric speech recognition,” EURASIP J. Audio, Speech, Music Process., vol. 2023, no. 48, 2023, [Online]. Available: https://link.springer.com/article/10.1186/s13636-023-00318-2
Neethu Mariam Joy, S. Umesh, “On Improving Acoustic Models for TORGO Dysarthric Speech Database,” Proc. Annu. Conf. Int. Speech Commun. Assoc. INTERSPEECH, 2017, doi: 10.21437/Interspeech.2017-878.
Guilherme Schu, Parvaneh Janbakhshi, Ina Kodrasi, “On using the UA-Speech and TORGO databases to validate automatic dysarthric speech classification approaches,” arXiv:2211.08833, 2022, [Online]. Available: https://arxiv.org/abs/2211.08833
Neethu Mariam Joy, S. Umesh, “Improving Acoustic Models in TORGO Dysarthric Speech Database,” IEEE Trans. neural Syst. Rehabil. Eng. a Publ. IEEE Eng. Med. Biol. Soc., 2018, [Online]. Available: https://www.researchgate.net/publication/322965619_Improving_Acoustic_Models_in_TORGO_Dysarthric_Speech_Database
Xueyuan Chen, Yuejiao Wang, Xixin Wu, Disong Wang, Zhiyong Wu, Xunying Liu, Helen Meng, “Exploiting Audio-Visual Features with Pretrained AV-HuBERT for Multi-Modal Dysarthric Speech Reconstruction,” arXiv:2401.17796, 2024, [Online]. Available: https://arxiv.org/abs/2401.17796
E. Hermann and M. Magimai-Doss, “Dysarthric Speech Recognition with Lattice-Free MMI,” ICASSP, IEEE Int. Conf. Acoust. Speech Signal Process. - Proc., vol. 2020-May, pp. 6109–6113, May 2020, doi: 10.1109/ICASSP40776.2020.9053549.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 50sea

This work is licensed under a Creative Commons Attribution 4.0 International License.















