
Detecting Fake Reviews in Roman Urdu Using Transformer Based Language Models
Keywords:
Roman Urdu, Fake Review Detection, NLP, BERT, XLM RAbstract
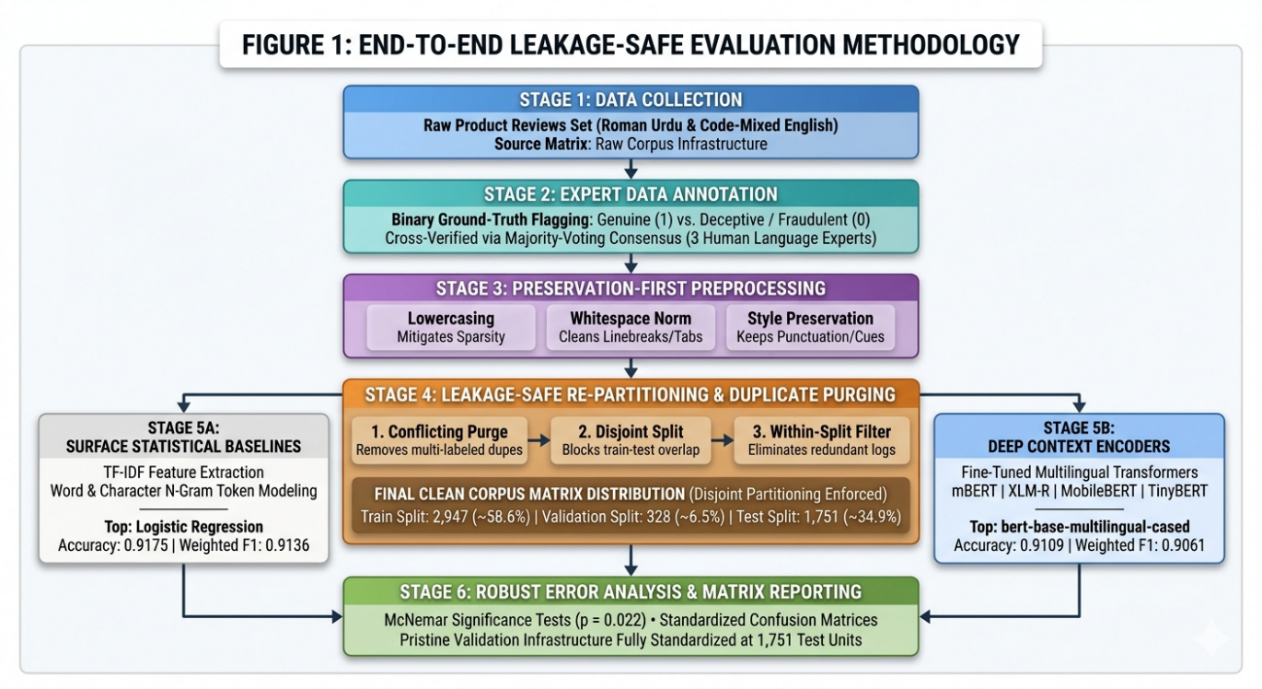
Reviews on online platforms face growing threats from deceptive content published by malicious users, which affects marketplace integrity. While widely used in South Asian e-commerce, Roman Urdu remains less explored due to non-standard conventions of spellings and frequent code mixing with English which weaken standard NLP pipelines. This paper introduces a Roman Urdu fake review detection corpus, RU-FRDC, which contains 5,026 samples annotated into fake and real classes. The dataset shows a realistic 2.53:1 imbalance ratio, containing 3,602 real and 1,424 fake instances. To counter evaluation biases, we propose a leakage-safe protocol which removes duplicates and enforces disjoint train (2,947), validation (328), and test (1,751) splits. Using this protocol, we evaluate lexical baselines against multiple fine-tuned transformers. Our best model, TF-IDF with Logistic Regression, achieved the highest overall efficacy with 0.9175 accuracy, weighted F1 score 0.9136, and a macro F1 score of 0.8878. Importantly, it balances precision and recall by maintaining a remarkably low false positive count1 (FP=7) at the expense of 143 false negatives, which demonstrates a conservative minority class flagging behavior. This close outcome is plausible for Roman Urdu review text because reviews are often short and sentiment heavy, and fake reviews commonly reuse a limited set of promotional templates. Under such conditions, TF IDF models can capture repeated phrases and common deception patterns effectively, especially when evaluation is leakage-safe and duplicates are controlled. Among the fine-tuned transformer networks, the multilingual encoder XLM-RoBERTa (XLM-RoBERTa-base) achieves the highest performance with a classification accuracy of 0.9143 and a weighted F1 score of 0.9096, which is followed closely by bert base multilingual cased at 0.9109 accuracy and a weighted F1 score of 0.9061.
References
Sampoorna Poria, Xiaolei Huang, “Bhaasha, Bhāṣā, Zaban: A Survey for Low-Resourced Languages in South Asia – Current Stage and Challenges,” arXiv:2509.11570v1, 2025, [Online]. Available: https://arxiv.org/html/2509.11570v1
Peter von Philipsborn, Jan M. Stratil, “Environmental interventions to reduce the consumption of sugar‐sweetened beverages and their effects on health,” Cochrane Database Syst. Rev., 2019, doi: 10.1002/14651858.CD012292.pub2.
M. Tasadduq, “Lexical Normalization of Roman Urdu,” 2022 24th Int. Multitopic Conf. INMIC 2022, 2022, doi: 10.1109/INMIC56986.2022.9972968.
“Memorization vs. Generalization : Quantifying Data Leakage in NLP Performance Evaluation | Request PDF.” Accessed: Jun. 20, 2026. [Online]. Available: https://www.researchgate.net/publication/355429440_Memorization_vs_Generalization_Quantifying_Data_Leakage_in_NLP_Performance_Evaluation
J. A. Haagsma, P. L. Geenen, “Community incidence of pathogen-specific gastroenteritis: reconstructing the surveillance pyramid for seven pathogens in seven European Union member states,” Epidemiol. Infect., vol. 141, no. 8, 2013, doi: 10.1017/S0950268812002166.
“What Yelp Fake Review Filter Might Be Doing? | Request PDF.” Accessed: Jun. 20, 2026. [Online]. Available: https://www.researchgate.net/publication/288582292_What_yelp_fake_review_filter_might_be_doing
M. Ott, Y. Choi, C. Cardie, and J. T. Hancock, “Finding Deceptive Opinion Spam by Any Stretch of the Imagination,” ACL-HLT 2011 - Proc. 49th Annu. Meet. Assoc. Comput. Linguist. Hum. Lang. Technol., vol. 1, pp. 309–319, Jul. 2011, Accessed: Dec. 25, 2023. [Online]. Available: https://arxiv.org/abs/1107.4557v1
“(PDF) A Survey on Review Spam Detection Methods using Deep Learning Approach.” Accessed: Jun. 20, 2026. [Online]. Available: https://www.researchgate.net/publication/402882098_A_Survey_on_Review_Spam_Detection_Methods_using_Deep_Learning_Approach
“(PDF) Identification of Real and Fake Reviews Written in Roman Urdu.” Accessed: May 31, 2026. [Online]. Available: https://www.researchgate.net/publication/377077849_Identification_of_Real_and_Fake_Reviews_Written_in_Roman_Urdu
Rabail Zahid, Muhammad Owais Idrees, “Roman Urdu reviews dataset for aspect based opinion mining,” Proc. - 2020 35th IEEE/ACM Int. Conf. Autom. Softw. Eng. Work. ASEW 2020, 2021, [Online]. Available: https://dl.acm.org/doi/10.1145/3417113.3423377
Ahmer Tabassum, Sarfraz Ahmad, “UrduMMLU: A Massive Multitask Benchmark for Urdu Language Understanding,” arXiv:2606.07167v1, 2026, [Online]. Available: https://arxiv.org/html/2606.07167v1
E. Enfes, N. Awwad and K. J. Adebayo, “Cross-Dialectal Transfer Learning for Offensive Language Detection in Arabic,” IEEE Access, vol. 14, pp. 48182–48197, 2026, doi: 10.1109/ACCESS.2026.3678206.
Sheetal Harris, Jinshuo Liu, Hassan Jalil Hadi, Yue Cao, “Ax-to-Grind Urdu: Benchmark Dataset for Urdu Fake News Detection,” arXiv:2403.14037, 2024, [Online]. Available: https://arxiv.org/abs/2403.14037
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, “Unsupervised Cross-lingual Representation Learning at Scale,” arXiv:1911.02116, 2020, [Online]. Available: https://arxiv.org/abs/1911.02116
K. T. Jacob Devlin, Ming-Wei Chang, Kenton Lee, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” NAACL HLT 2019 - 2019 Conf. North Am. Chapter Assoc. Comput. Linguist. Hum. Lang. Technol. - Proc. Conf., 2019, doi: https://doi.org/10.48550/arXiv.1810.04805.
M. Amjad, G. Sidorov, A. Zhila, H. Gómez-Adorno, I. Voronkov, and A. Gelbukh, “‘Bend the truth’: Benchmark dataset for fake news detection in Urdu language and its evaluation,” J. Intell. Fuzzy Syst., vol. 39, no. 2, pp. 2457–2469, Jun. 2020, doi: 10.3233/JIFS-179905;JOURNAL:JOURNAL:IFSA;REQUESTEDJOURNAL:JOURNAL:IFSA;PAGE:STRING:ARTICLE/CHAPTER.
Mubasher Malik, Hamid Ghous, “Sentiment Analysis of Roman Urdu Text Using Machine Learning Techniques,” Innov. Comput. Rev., vol. 3, no. 2, 2023, doi: 10.32350/icr.32.05.
Bilal Chandio, Asadullah Shaikh, “Sentiment Analysis of Roman Urdu on E-Commerce Reviews Using Machine Learning,” C. - Comput. Model. Eng. Sci., vol. 131, 2022, doi: 10.32604/cmes.2022.019535.
Muhammad Bilal, Atif Khan, “Roman Urdu Hate Speech Detection Using Transformer-Based Model for Cyber Security Applications,” Sensors, vol. 23, no. 8, p. 3909, 2023, doi: https://doi.org/10.3390/s23083909.
Shyam Sundar Debsarkar, V. B.Surya Prasath, “A multi-expert deep learning framework with LLM-guided arbitration for multimodal histopathology prediction,” Comput. Med. Imaging Graph., vol. 128, p. 102704, 2026, doi: https://doi.org/10.1016/j.compmedimag.2026.102704.
Sihem Nouas, Lamia Oukid, “Enhancing imbalanced text classification: an overlap-based refinement approach,” Data Sci. Manag., vol. 8, no. 4, pp. 474–484, 2025, doi: https://doi.org/10.1016/j.dsm.2025.03.001.
“(PDF) Optimizing Hyperparameters in Machine Learning Models: Techniques and Best Practices.” Accessed: Jun. 20, 2026. [Online]. Available: https://www.researchgate.net/publication/386453033_Optimizing_Hyperparameters_in_Machine_Learning_Models_Techniques_and_Best_Practices
“(PDF) An Empirical Study on the Correlation between Early Stopping Patience and Epochs in Deep Learning.” Accessed: Jun. 20, 2026. [Online]. Available: https://www.researchgate.net/publication/382025156_An_Empirical_Study_on_the_Correlation_between_Early_Stopping_Patience_and_Epochs_in_Deep_Learning
Tanjil Hasan Sakib, Md. Tanzib Hosain, “Small Language Models: Architectures, Techniques, Evaluation, Problems and Future Adaptation,” arXiv:2505.19529v2, 2025, [Online]. Available: https://arxiv.org/html/2505.19529v2
Grigori Sidorov, Francisco Velasquez, “Syntactic N-grams as machine learning features for natural language processing,” Expert Syst. Appl., vol. 41, no. 3, 2014, doi: 10.1016/j.eswa.2013.08.015.
K. Archchitha and E. Y. A. Charles, “Opinion Spam Detection in Online Reviews Using Neural Networks,” 19th Int. Conf. Adv. ICT Emerg. Reg. ICTer 2019 - Proc., Sep. 2019, doi: 10.1109/ICTER48817.2019.9023695.
“Understanding Open Source vs. Closed Source in AI.” Accessed: Jun. 20, 2026. [Online]. Available: https://blog.udemy.com/open-source-vs-closed-source-ai/
S. Nitheeshwari, T. Malar, and R. Abirami, “Hybrid AI-Driven Content Moderation,” 2025 IEEE 9th Int. Conf. Inf. Commun. Technol. CICT 2025, 2025, doi: 10.1109/CICT67193.2025.11399201.
Shebuti Rayana, Leman Akoglu, “Collective Opinion Spam Detection: Bridging Review Networks and Metadata,” Proc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., 2015, [Online]. Available: https://dl.acm.org/doi/10.1145/2783258.2783370
Naveed Hussain, Hamid Turab Mirza, “Spam Review Detection Using the Linguistic and Spammer Behavioral Methods,” IEEE Access, 2020, doi: 10.1109/ACCESS.2020.2979226.
Hojjat Aghakhani, Aravind Machiry, Shirin Nilizadeh, Christopher Kruegel, Giovanni Vigna, “Detecting Deceptive Reviews using Generative Adversarial Networks,” arXiv:1805.10364, 2018, [Online]. Available: https://arxiv.org/abs/1805.10364
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 50sea

This work is licensed under a Creative Commons Attribution 4.0 International License.















