
Low-Resource Generative AI: Model Optimization for Edge and Mobile Devices
Keywords:
Edge AI Deployment, Model Optimization, Generative AI Compression, Low-Power Interface, Resource-Constrained DevicesAbstract
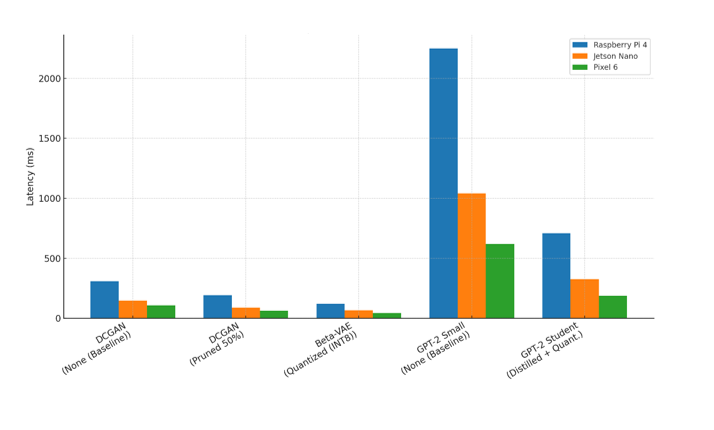
The effective deployment of generative AI models in real-time applications has been impeded by the computational and memory requirements of Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and transformer-based models. We investigate the deployment of generative models on low-resource hardware (edge devices, mobile devices) using optimization techniques such as pruning, quantization, and knowledge distillation. In this study, we defined a detailed experimental framework to measure the performance of the studied methods against standard benchmarks, including CIFAR-10, CelebA, and OpenWebText, across heterogeneous hardware platforms ranging from the Raspberry Pi 4 and Jetson Nano to the Google Pixel 6. The results demonstrate that applying pruning techniques reduces model parameters by approximately 50 percent without statistically significant degradation in output quality. In contrast, quantization significantly decreases both inference latency and power consumption by 70.3 ± 3.2% and 61.7 ± 4.1%, respectively. Additionally, knowledge distillation methods compress transformer architectures while maintaining acceptable perplexity values. Collectively, these optimizations reduce inference time by up to 70 percent and energy consumption by more than 60 percent, supporting the feasibility of deploying generative artificial intelligence on devices with constrained processing and energy resources. Practically, these findings have implications for the successful deployment of useful, privacy-preserving, and portable AI across a wide range of application domains such as health, communications, and education.
References
A. Howard et al., “Searching for MobileNetV3,” Proc. IEEE Int. Conf. Comput. Vis., vol. 2019-October, pp. 1314–1324, May 2019, doi: 10.1109/ICCV.2019.00140.
Xu Han, Zhengyan Zhang, “Pre-trained models: Past, present and future,” AI Open, vol. 2, pp. 225–250, 2021, doi: https://doi.org/10.1016/j.aiopen.2021.08.002.
Canwen Xu, Wangchunshu Zhou, Tao Ge, Furu Wei, Ming Zhou, “BERT-of-Theseus: Compressing BERT by Progressive Module Replacing,” arXiv:2002.02925, 2020, [Online]. Available: https://arxiv.org/abs/2002.02925
Y. Cheng, D. Wang, P. Zhou, and T. Zhang, “Model Compression and Acceleration for Deep Neural Networks: The Principles, Progress, and Challenges,” IEEE Signal Process. Mag., vol. 35, no. 1, pp. 126–136, Jan. 2018, doi: 10.1109/MSP.2017.2765695.
Geoffrey Hinton, Oriol Vinyals, Jeff Dean, “Distilling the Knowledge in a Neural Network,” arXiv:1503.02531, 2015, [Online]. Available: https://arxiv.org/abs/1503.02531
A. G. Howard et al., “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,” Apr. 2017, doi: 10.48550/arxiv.1704.04861.
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, Qun Liu, “TinyBERT: Distilling BERT for Natural Language Understanding,” arXiv:1909.10351, 2019, [Online]. Available: https://arxiv.org/abs/1909.10351
Siqi Sun, Yu Cheng, Zhe Gan, Jingjing Liu, “Patient knowledge distillation for bert model compression,” arXiv:1908.09355, 2019, [Online]. Available: https://arxiv.org/abs/1908.09355
Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, Quoc V. Le, “Mnasnet: Platform-aware neural architecture search for mobile,” arXiv:1807.11626, 2018, [Online]. Available: https://arxiv.org/abs/1807.11626
Emma Strubell, Ananya Ganesh, Andrew McCallum, “Energy and policy considerations for deep learning in NLP,” arXiv:1906.02243, 2019, [Online]. Available: https://arxiv.org/abs/1906.02243
A. Radford, L. Metz, and S. Chintala, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,” Int. Conf. Learn. Represent., 2015.
Jacob Sander, Achraf Cohen, Venkat R. Dasari, Brent Venable, Brian Jalaian, “On Accelerating Edge AI: Optimizing Resource-Constrained Environments,” arXiv:2501.15014, 2025, [Online]. Available: https://arxiv.org/abs/2501.15014
W. J. D. Song Han, Huizi Mao, “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding,” arXiv:1510.00149, 2015, [Online]. Available: https://arxiv.org/abs/1510.00149
Yehui Tang, Kai Han, Yunhe Wang, Chang Xu, Jianyuan Guo, Chao Xu, Dacheng Tao, “Patch slimming for efficient vision transformers,” arXiv:2106.02852, 2021, [Online]. Available: https://arxiv.org/abs/2106.02852
Jonathan Frankle, Michael Carbin, “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks,” arXiv:1803.03635, 2018, [Online]. Available: https://arxiv.org/abs/1803.03635
Ofir Zafrir, Guy Boudoukh, Peter Izsak, Moshe Wasserblat, “Q8BERT: Quantized 8Bit BERT,” arXiv:1910.06188, 2019, [Online]. Available: https://arxiv.org/abs/1910.06188
Defu Liu, Yixiao Zhu, “A survey of model compression techniques: past, present, and future. Front. Robot,” Front. Robot. AI, vol. 12, 2025, doi: https://doi.org/10.3389/frobt.2025.1518965.
R. Zhang et al., “Toward Democratized Generative AI in Next-Generation Mobile Edge Networks,” IEEE Netw., vol. 39, no. 6, pp. 251–260, 2025, doi: 10.1109/MNET.2025.3541078.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 50sea

This work is licensed under a Creative Commons Attribution 4.0 International License.















